
.webp?width=2917&height=1250&name=What%20is%20Data%20Augmentation%20in%20Deep%20Learning%20(1).webp)
The accuracy of deep learning models depends upon the quality, quantity, and contextual meaning of the training data set. However, the scarcity of this up-to-the-market data set is one of the major challenges in building DL models.
Producing a data set to feed the training model could be a time-consuming and costly affair for organizations. That is why the AI teams leverage the benefits of Data Augmentation techniques.
Data Augmentation is a set of techniques that enable AI teams to artificially generate new data points from the data that already exists. This practice includes making small changes to the data (which could either be a text, audio, or visual), generating diverse instances, and expanding the data set to have improved the performance and outcome of the deep learning model.
For example, Data augmentation methods reduce data overfitting which significantly improves the accuracy rate and generalizes the output of a model.
Data overfitting happens when a model is trained too well for a set of data. In this case, the model learns the noise and detail of the data to an extent that it starts to impact the performance of the model on new data. This means that the noise and fluctuations in the training data are learned as concepts by the model.
When a new set of data is added to the model, the learned concepts do not apply to it, which negatively impacts the ability of a model to generalize. This is generally the problem with small data sets. The smaller the data sets, the more is the control of networks over it. But when the size of a data increases through augmentation, the network doesn’t overfit the training data set and is thus forced to generalize.
Data augmentation technique is adopted in almost every deep learning application such as image classification, object detection, natural language processing, image recognition, semantic segmentation, etc.
Data Augmentation Techniques to Expand Deep Learning Data Set
For augmenting the deep learning data sets, there are several techniques that can be adapted based on the type of data. We will discuss some of the techniques that can be used for augmenting images, text, and audio data.
Image Augmentation:
If there are images in the data set, the following techniques can be used for expanding the size of the data:
- Geometric transformations: The images can be randomly flipped, cropped, scaled, or rotated
 Random rotation of an image | Github
Random rotation of an image | Github
- Color space transformations: Changes are made in RGB colors or colors are intensified
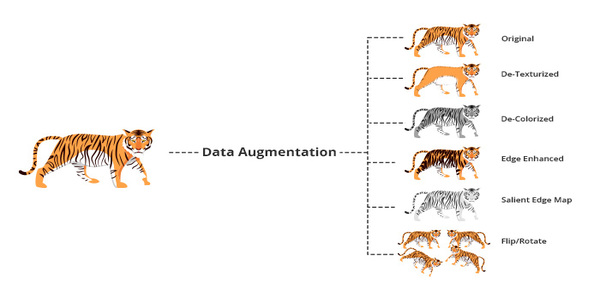
- Kernel filters: Images are sharpened or blurred

- Image mixing: Images are mixed with one another

Text Data Augmentation:
Text data augmentation can be done at the character level, word level, phrase level, and sentence level. Changes in text data can be made by word or sentence shuffling, word replacement, syntax tree manipulation, etc. Following are some of the techniques that are used for augmenting text data:
- Easy Data Augmentation (EDA)
In this method to augment data, some easy text transformations are applied. For example, a word is randomly replaced with a synonym. Two or more words are swapped in the sentence. For an NLP solution, the EDA technique helps in:
1. Replacing words with synonyms
2. Words or sentence shuffling
3. Text substitution
4. Random insertion, deletion, or swapping of words
- Back Translation
Back translation, also known as reverse translation is the process of re-translating content from a target language back to its source language. This leads to variants of a sentence that help the model to learn better.
|
English: How are you? |
Arabic: kayf halukum |
English: How are you all |
|
English: This is awesome |
Italian: Questo e spettacolare |
English: This is spectacular |
- Generative Adversarial Networks (GAN)
GAN is an unsupervised learning network that involves automatically discovering and learning the regularities or patterns in input data. The model thus generates new examples that could have been apparently drawn from the original data set.
The pandas have… |
The pandas have different eyes than bears |
|
The pandas can swim and climb |
|
|
The pandas spend a lot of their day eating |
Audio Data Augmentation
For audio data augmentation, noise injection, shifting, changing the speed of the tape, etc. are some of the techniques used for augmenting data.
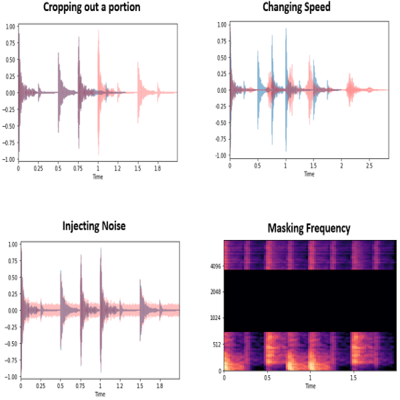
Audio augmentation | Source: Github
Top 14 Industry Applications of Data Augmentation
Let's delve deeper into the applications of data augmentation across various industries, exploring specific use cases and the impact on model performance:
1. Computer Vision:
- Object Detection and Localization: In retail, computer vision models benefit from data augmentation techniques like random scaling and cropping, enabling them to accurately detect and localize products of varying sizes and positions on store shelves.
- Autonomous Vehicles: Data augmentation is critical for training models in autonomous driving scenarios. Simulating diverse weather conditions, lighting variations, and traffic situations helps develop robust models capable of handling real-world complexities.

2. Natural Language Processing (NLP):
- Named Entity Recognition (NER): In the healthcare industry, NLP models for extracting entities like diseases, medications, and symptoms from clinical notes benefit from data augmentation. This ensures the models can handle a wide range of medical terminologies and writing styles.
- Language Translation: Augmenting parallel corpora with diverse sentence structures and word choices is essential for improving the accuracy of language translation models, particularly in industries dealing with multilingual content.
3. Healthcare:
- Radiology Image Segmentation: Data augmentation is indispensable for training models in medical image segmentation, a crucial task in identifying and delineating organs or abnormalities. Augmenting 3D medical images aids in better understanding spatial relationships.
- Drug Discovery: In pharmaceutical research, augmentation is applied to chemical and biological datasets. It helps models predict molecular properties, optimize drug candidates, and simulate the effects of different chemical modifications.
4. Audio Processing:
- Voice Biometrics: Data augmentation is vital for training voice biometrics systems, ensuring accurate speaker identification across diverse vocal characteristics, accents, and background noises.
- Environmental Sound Analysis: Models for environmental sound analysis, used in industries like conservation and urban planning, benefit from data augmentation to recognize sounds from various sources and under different environmental conditions.
5. Finance:
- Fraud Detection: Augmenting financial transaction data is crucial for training fraud detection models. Simulating diverse transaction patterns and anomalies ensures models are adept at identifying fraudulent activities in real-time.
- Portfolio Optimization: In quantitative finance, data augmentation helps model the behavior of financial instruments under different market conditions, supporting the development of robust portfolio optimization strategies.
6. Manufacturing:
- Defect Detection in Manufacturing: Data augmentation is extensively used for training models to detect defects in manufactured products. Simulating various types, shapes, and sizes of defects ensures the model's ability to identify anomalies accurately.
- Supply Chain Optimization: Augmenting data related to supply chain operations helps models predict demand, optimize inventory levels, and enhance overall supply chain efficiency.
7. Retail:
- Visual Search: Data augmentation is crucial for enhancing visual search capabilities in e-commerce. Models trained on augmented images can effectively match user-uploaded images with products in the catalog, even when the images exhibit variations in lighting, angle, or background.
- Virtual Try-On: In the fashion industry, data augmentation is employed in virtual try-on applications. Models can simulate different body types, poses, and clothing variations, providing a realistic virtual shopping experience.
ALSO READ: The Future of Personalized Shopping: Virtual Clothes Try-On using AI
How to Augment Data Using Deep Learning Frameworks
1. TensorFlow
TensorFlow provides a robust set of image processing operations through the tf.image module. This module includes functions for common augmentations such as flips, rotations, zooms, and color adjustments.
Example code:
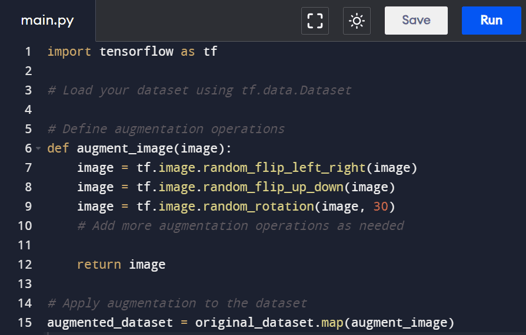
In this example, augment_image is a function that applies random left-right and up-down flips, as well as random rotations to each image in the dataset. Users can easily customize and combine these operations based on the requirements of their specific task.
2. PyTorch
PyTorch, with its torchvision.transforms module, simplifies the process of applying data augmentations to images. The module includes various pre-defined transformations that can be composed to create a pipeline of augmentations.
Example code:
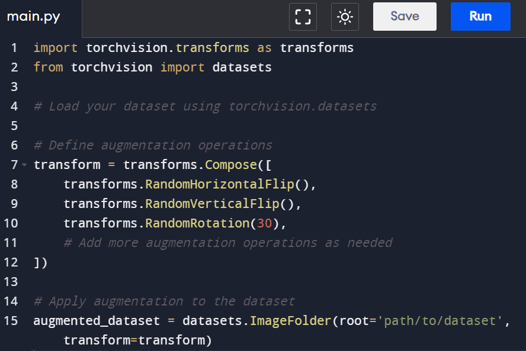
Here, the Compose function is used to combine different augmentation operations into a sequential transformation pipeline. Users have the flexibility to experiment with and customize the augmentation strategy.
3. Keras (with TensorFlow backend)
Keras, which can run on top of TensorFlow, offers a convenient ImageDataGenerator class that allows for real-time data augmentation during model training. It's particularly suitable for image data.
Example code:
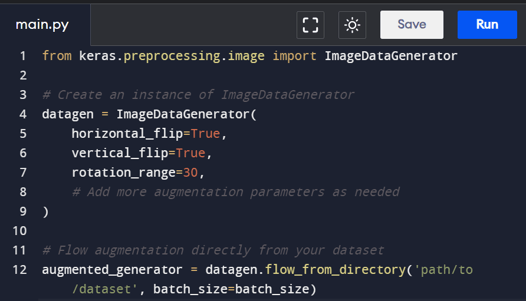
The ImageDataGenerator enables users to define augmentation parameters such as horizontal and vertical flips, rotations, and more. It generates augmented batches on-the-fly, making it efficient for large datasets.

Benefits of Data Augmentation
1. Improved Generalization
In deep learning, overfitting occurs when a model learns the training data too well, including its noise and outliers, and fails to generalize effectively to new, unseen data. Data augmentation acts as a regularizer by exposing the model to various augmented versions of the original data during training. This diverse input helps the model become more adaptable, reducing the risk of overfitting.
2. Enhanced Robustness
Data augmentation contributes to the creation of a more robust model that can handle variations and anomalies in the input data. In real-world applications, data is seldom uniform, and objects or patterns may appear in different orientations, lighting conditions, or scales. Through techniques like rotation, zooming, and brightness adjustment, data augmentation simulates these variations, enabling the model to recognize and respond to them appropriately.
This increased robustness is particularly valuable in scenarios where the test data may differ from the training data in unforeseen ways. Models trained with augmented data are better prepared to handle diverse inputs, leading to improved performance and reliability in practical applications.
3. Cost and Resource Savings
Collecting and annotating large datasets can be a time-consuming and expensive process. Data augmentation offers a cost-effective alternative by artificially expanding the size of the training dataset. With a relatively small original dataset, augmented versions can be generated on-the-fly during training, providing the model with a more extensive set of examples without the need for additional data collection.
4. Addressing Class Imbalance
In many real-world datasets, there's often an imbalance in the distribution of classes, where certain classes have significantly fewer examples than others. This class imbalance can lead to biased models that perform well on the majority class but struggle with minority classes.
By applying augmentation techniques selectively to minority classes, the model is exposed to a more balanced representation of each class during training. This assists the model in learning the distinguishing features of the minority classes, improving its ability to make accurate predictions for these less frequent instances. As a result, data augmentation becomes a valuable tool for tackling class imbalance and promoting fair and robust model performance across all classes.
5. Privacy Preservation in Sensitive Data
In scenarios where the training data contains sensitive information, such as medical records or personal details, data augmentation offers a privacy-preserving advantage. Instead of directly manipulating or exposing the original sensitive data, augmentation can be applied to generate synthetic variations that retain the statistical characteristics of the original data without compromising individual privacy.
For instance, in medical imaging, where patient data is sensitive, augmentation techniques like rotation, scaling, or flipping can be applied to generate diverse examples without revealing specific details about individual patients. This allows the development of robust models without risking the privacy and confidentiality of the underlying data.
6. Domain Adaptation
Data augmentation can be instrumental in domain adaptation, where the distribution of the training data differs from the distribution of the data the model will encounter in the real-world application. In scenarios like transferring a model trained on synthetic data to a real-world environment, data augmentation helps bridge the gap between the synthetic and real data distributions.
Data Augmentation for Neural Networks: Challenges Involved
Expanding a data set for improved performance and cost-saving is a good idea until the same is done by optimizing the augmentation cycle. It is a recommended practice to augment a data set in limits to have expected results.
While attempting to increase the size of the training data set, AI experts might experience the following challenges:
Impact on Training Duration: Augmenting the data using frameworks such as Keras, Tensorflow, PyTorch, etc. can impact the training duration of the data set. This is because new data is generated and added to the dataset will increase the efforts and time to train the data.
When data is added for training, it creates artificial clusters. In Deep Learning, clustering is a fundamental data analysis technique. While these clusters make learning efficient, they might not generalize the data efficiently. Therefore, the model might require training from scratch to achieve satisfactory results. It is recommended to augment the training data set with the optimum amount of data to have desired results and save time.
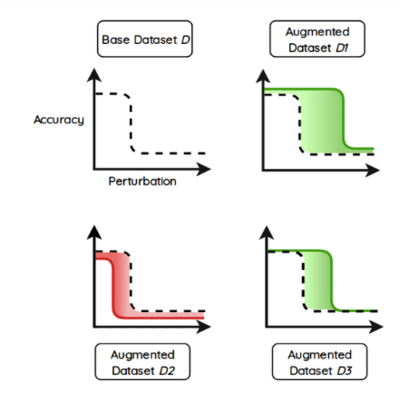
Impact of Performance Stability: Augmenting different data sets can lead to varying performance stability of the neural network. It’s the ability of a network to handle noise in the data set that has a positive impact on the performance of the network during the training phase.
It is important to select the correct parameters with which the dataset needs to be augmented. This will help to stabilize the augmented dataset as fast as possible and lessen the noise that usually impacts the performance.
Identifying Biased Dataset: A biased AI system is an anomaly in the deep learning algorithms that results in low accuracy levels, skewed outcomes, and analytical errors. Before executing data augmentation, it is necessary to test the data set against ethical AI principles as an anomaly, when multiplied can lead to a high-inaccuracy rate in the output.
The Wrap:
For augmenting data sets, there are several libraries that are available to the AI software development teams. Augmentor, Torchvision, imgaug are some of the libraries for image augmentation. Similarly, there is NLPau for creating a variety in the text data sets.
Data augmentation is a significant practice in an AI software development cycle. At Daffodil, our AI specialists practice this technique to create accurate and performance-rich ML and NLP algorithms.
However, to make the most of this data expansion technique, it is important to augment the data qualitatively. If your augmentation efforts are not reaping the expected accuracy and performance level, then there is an opportunity to connect with our experts who can help your team achieve the expected development outcome.




