

Have you noticed the ‘Smart Compose’ feature in Gmail that gives auto-suggestions to complete sentences while writing an email? This is one of the various use-cases of language models used in Natural Language Processing (NLP).
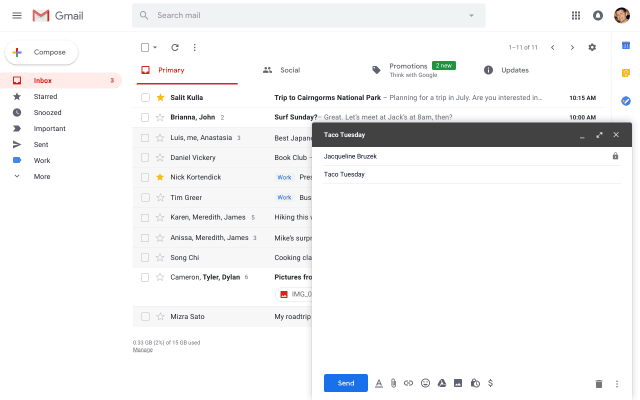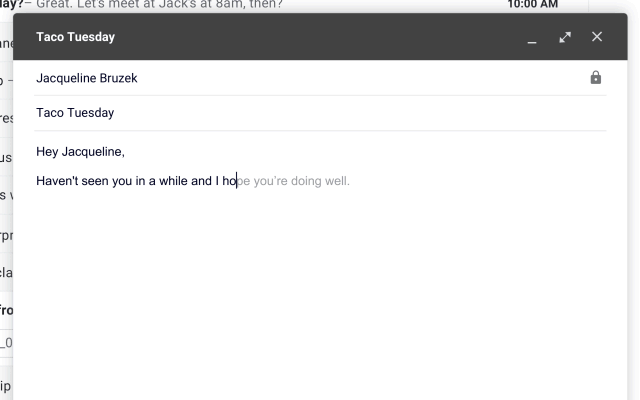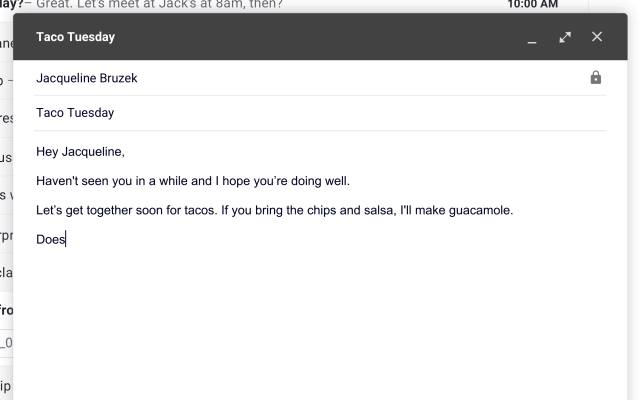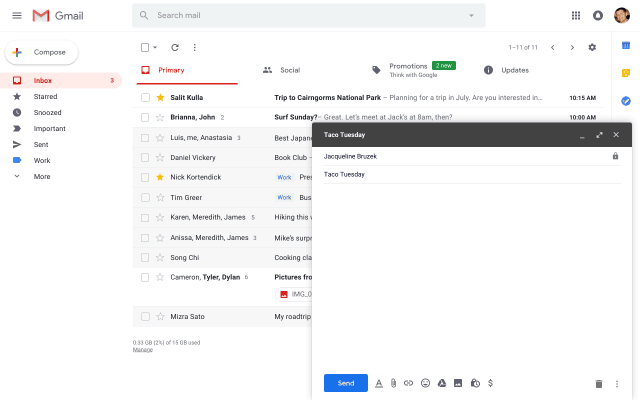
Image source: Google
A language model is the core component of modern Natural Language Processing (NLP). It’s a statistical model that is designed to analyze the pattern of human language and predict the likelihood of a sequence of words or tokens.
NLP-based applications use language models for a variety of tasks, such as audio to text conversion, speech recognition, sentiment analysis, summarization, spell correction, etc.
Let’s understand how language models help in processing these NLP tasks:
- Speech Recognition: Smart speakers, such as Alexa, use automatic speech recognition (ASR) mechanisms for translating the speech into text. It translates the spoken words into text and between this translation, the ASR mechanism analyzes the intent/sentiments of the user by differentiating between the words. For example, analyzing homophone phrases such as “Let her” or “Letter”, “But her” “Butter”.
- Machine Translation: When translating a Chinese phrase “我在吃” into English, the translator can give several choices as output:
I eat lunch
I am eating
Me am eating
Eating am I
Here, the language model tells that the translation “I am eating” sounds natural and will suggest the same as output.
Challenges with Language Modeling?
Formal languages (like a programming language) are precisely defined. All the words and their usage is predefined in the system. Anyone who knows a specific programming language can understand what’s written without any formal specification.
Natural language, on the other hand, isn’t designed; it evolves according to the convenience and learning of an individual. There are several terms in natural language that can be used in a number of ways. This introduces ambiguity but can still be understood by humans.
Machines only understand the language of numbers. For creating language models, it is necessary to convert all the words into a sequence of numbers. For the modellers, this is known as encodings.
Encodings can be simple or complex. Generally, a number is assigned to every word and this is called label-encoding. In the sentence “I love to play cricket on weekends”, every word is assigned a number [1, 2, 3, 4, 5, 6]. This is an example of how encoding is done (one-hot encoding).

How does Language Model Works?
Language Models determine the probability of the next word by analyzing the text in data. These models interpret the data by feeding it through algorithms.
The algorithms are responsible for creating rules for the context in natural language. The models are prepared for the prediction of words by learning the features and characteristics of a language. With this learning, the model prepares itself for understanding phrases and predicting the next words in sentences.
For training a language model, a number of probabilistic approaches are used. These approaches vary on the basis of the purpose for which a language model is created. The amount of text data to be analyzed and the math applied for analysis makes a difference in the approach followed for creating and training a language model.
For example, a language model used for predicting the next word in a search query will be absolutely different from those used in predicting the next word in a long document (such as Google Docs). The approach followed to train the model would be unique in both cases.
Types of Language Models:
There are primarily two types of language models:
1. Statistical Language Models
Statistical models include the development of probabilistic models that are able to predict the next word in the sequence, given the words that precede it. A number of statistical language models are in use already. Let’s take a look at some of those popular models:
N-Gram: This is one of the simplest approaches to language modelling. Here, a probability distribution for a sequence of ‘n’ is created, where ‘n’ can be any number and defines the size of the gram (or sequence of words being assigned a probability). If n=4, a gram may look like: “can you help me”. Basically, ‘n’ is the amount of context that the model is trained to consider. There are different types of N-Gram models such as unigrams, bigrams, trigrams, etc.
Unigram: The unigram is the simplest type of language model. It doesn't look at any conditioning context in its calculations. It evaluates each word or term independently. Unigram models commonly handle language processing tasks such as information retrieval. The unigram is the foundation of a more specific model variant called the query likelihood model, which uses information retrieval to examine a pool of documents and match the most relevant one to a specific query.
Bidirectional: Unlike n-gram models, which analyze text in one direction (backwards), bidirectional models analyze text in both directions, backwards and forwards. These models can predict any word in a sentence or body of text by using every other word in the text. Examining text bidirectionally increases result accuracy. This type is often utilized in machine learning and speech generation applications. For example, Google uses a bidirectional model to process search queries.
Exponential: This type of statistical model evaluates text by using an equation which is a combination of n-grams and feature functions. Here the features and parameters of the desired results are already specified. The model is based on the principle of entropy, which states that probability distribution with the most entropy is the best choice. Exponential models have fewer statistical assumptions which mean the chances of having accurate results are more.
Continuous Space: In this type of statistical model, words are arranged as a non-linear combination of weights in a neural network. The process of assigning weight to a word is known as word embedding. This type of model proves helpful in scenarios where the data set of words continues to become large and include unique words.
In cases where the data set is large and consists of rarely used or unique words, linear models such as n-gram do not work. This is because, with increasing words, the possible word sequences increase, and thus the patterns predicting the next word become weaker.
READ MORE: Top 15 Pre-Trained NLP Language Models
2. Neural Language Models
These language models are based on neural networks and are often considered as an advanced approach to execute NLP tasks. Neural language models overcome the shortcomings of classical models such as n-gram and are used for complex tasks such as speech recognition or machine translation.
Language is significantly complex and keeps on evolving. Therefore, the more complex the language model is, the better it would be at performing NLP tasks. Compared to the n-gram model, an exponential or continuous space model proves to be a better option for NLP tasks because they are designed to handle ambiguity and language variation.
Meanwhile, language models should be able to manage dependencies. For example, a model should be able to understand words derived from different languages.
Some Common Examples of Language Models
Language models are the cornerstone of Natural Language Processing (NLP) technology. We have been making the best of language models in our routine, without even realizing it. Let’s take a look at some of the examples of language models.
1. Speech Recognition
Voice assistants such as Siri and Alexa are examples of how language models help machines in processing speech audio.

2. Machine Translation
Google Translator and Microsoft Translate are examples of how NLP models can help in translating one language to another.
3. Sentiment Analysis
This helps in analyzing the sentiments behind a phrase. This use case of NLP models is used in products that allow businesses to understand a customer’s intent behind opinions or attitudes expressed in the text. Hubspot’s Service Hub is an example of how language models can help in sentiment analysis.
Moreover, it can be used to analyze social media posts to identify emerging trends, popular topics, and public sentiment in real-time.
Example: Trendinalia uses language models to process Twitter data, providing insights into trending hashtags, topics, and sentiment analysis, helping businesses understand public opinions and trends.
4. Text Suggestions
Google services such as Gmail or Google Docs use language models to help users get text suggestions while they compose an email or create long text documents, respectively.
5. Parsing Tools
Parsing involves analyzing sentences or words that comply with syntax or grammar rules. Spell checking tools are perfect examples of language modelling and parsing.
For example: Grammarly, it is a widely used writing assistant that employs advanced language models to correct grammar, spelling, and style errors in written text. It provides real-time suggestions and feedback as users type, helping them improve the clarity, coherence, and professionalism of their writing.
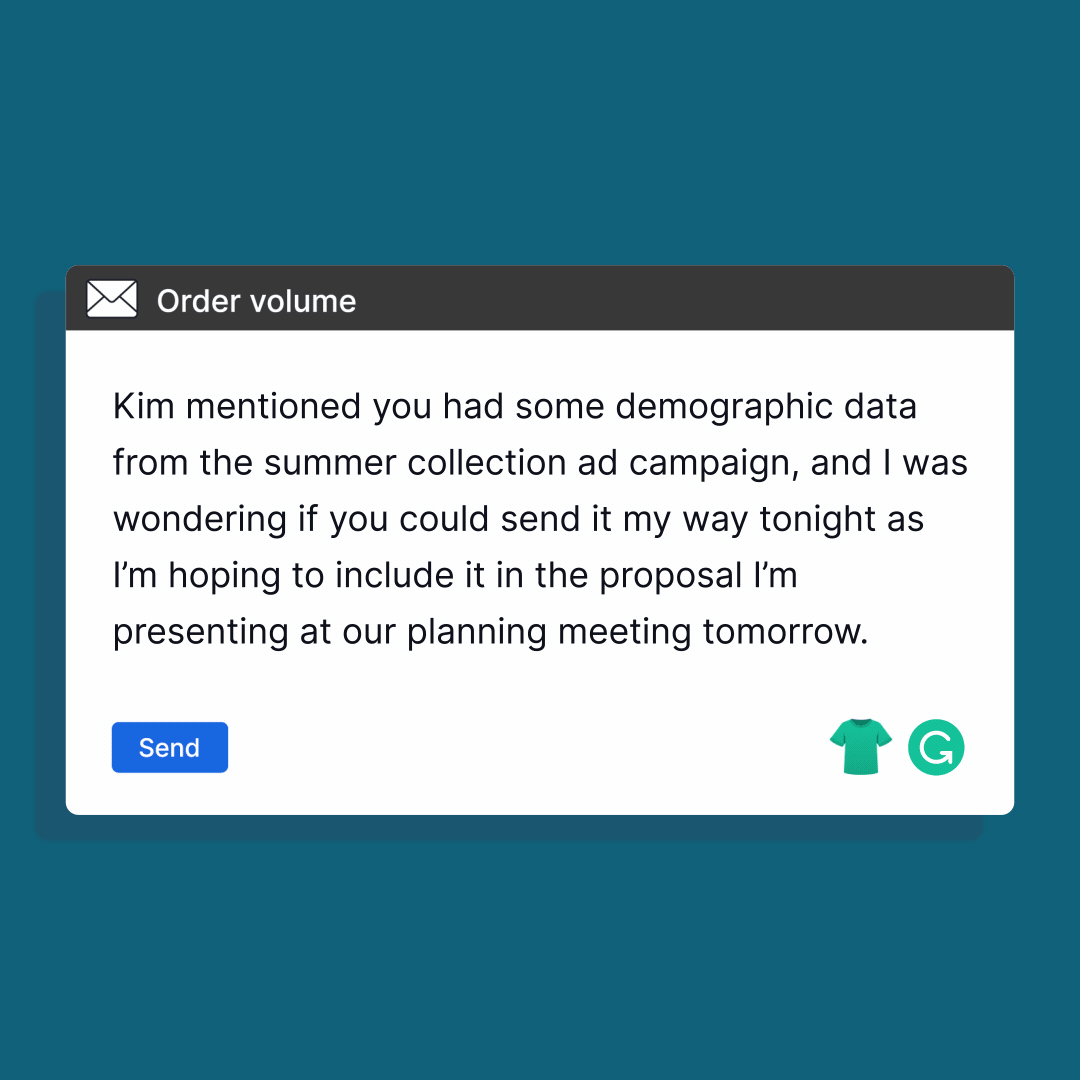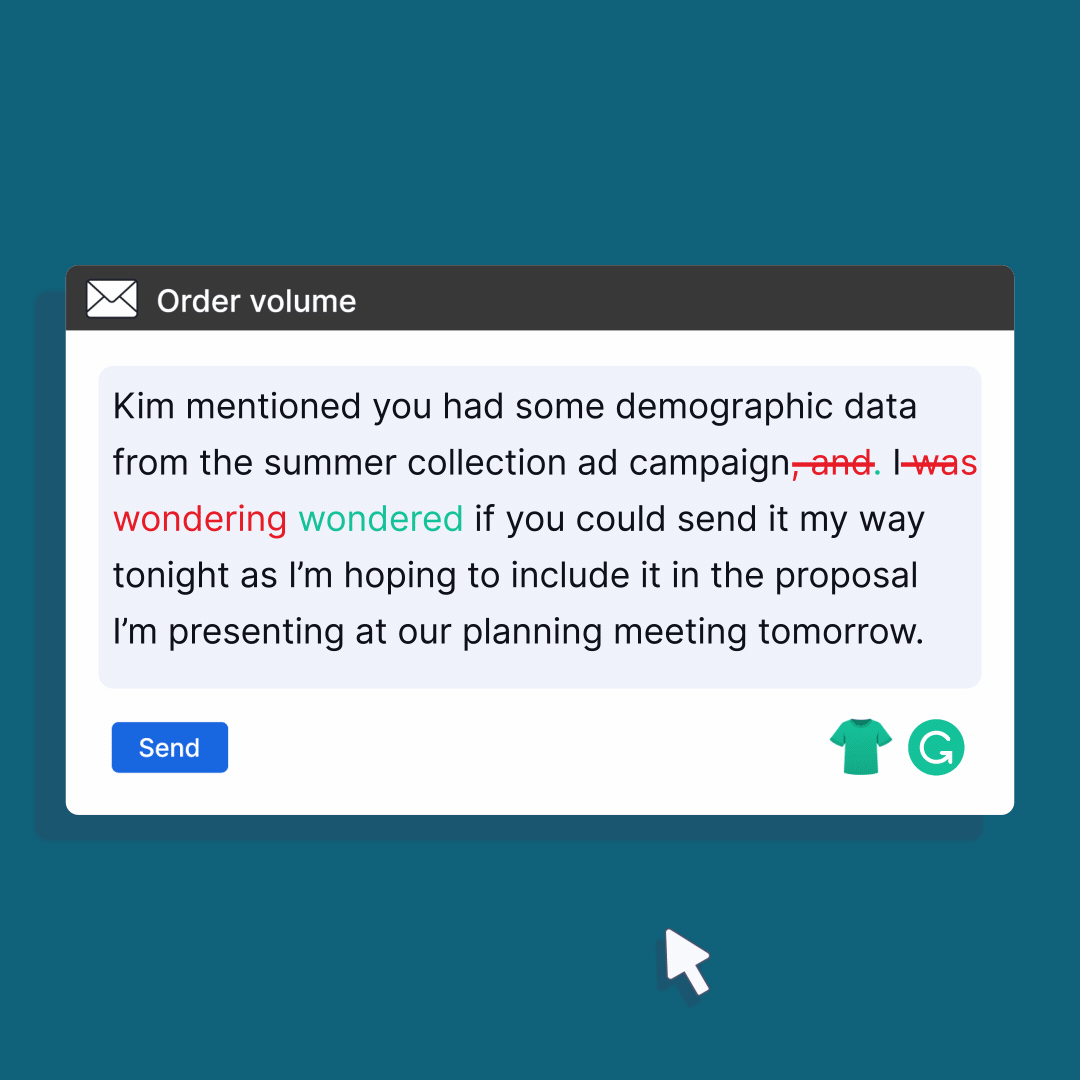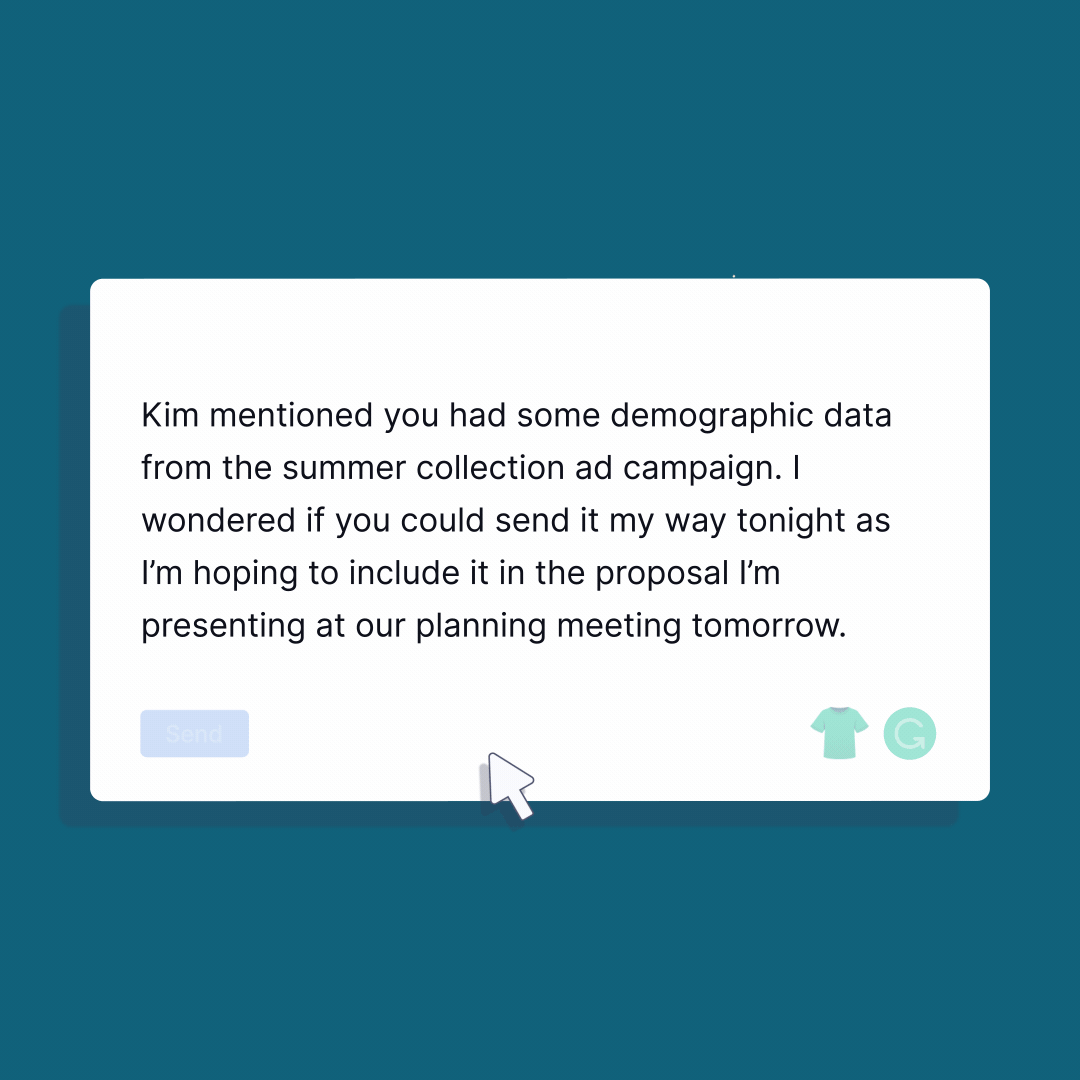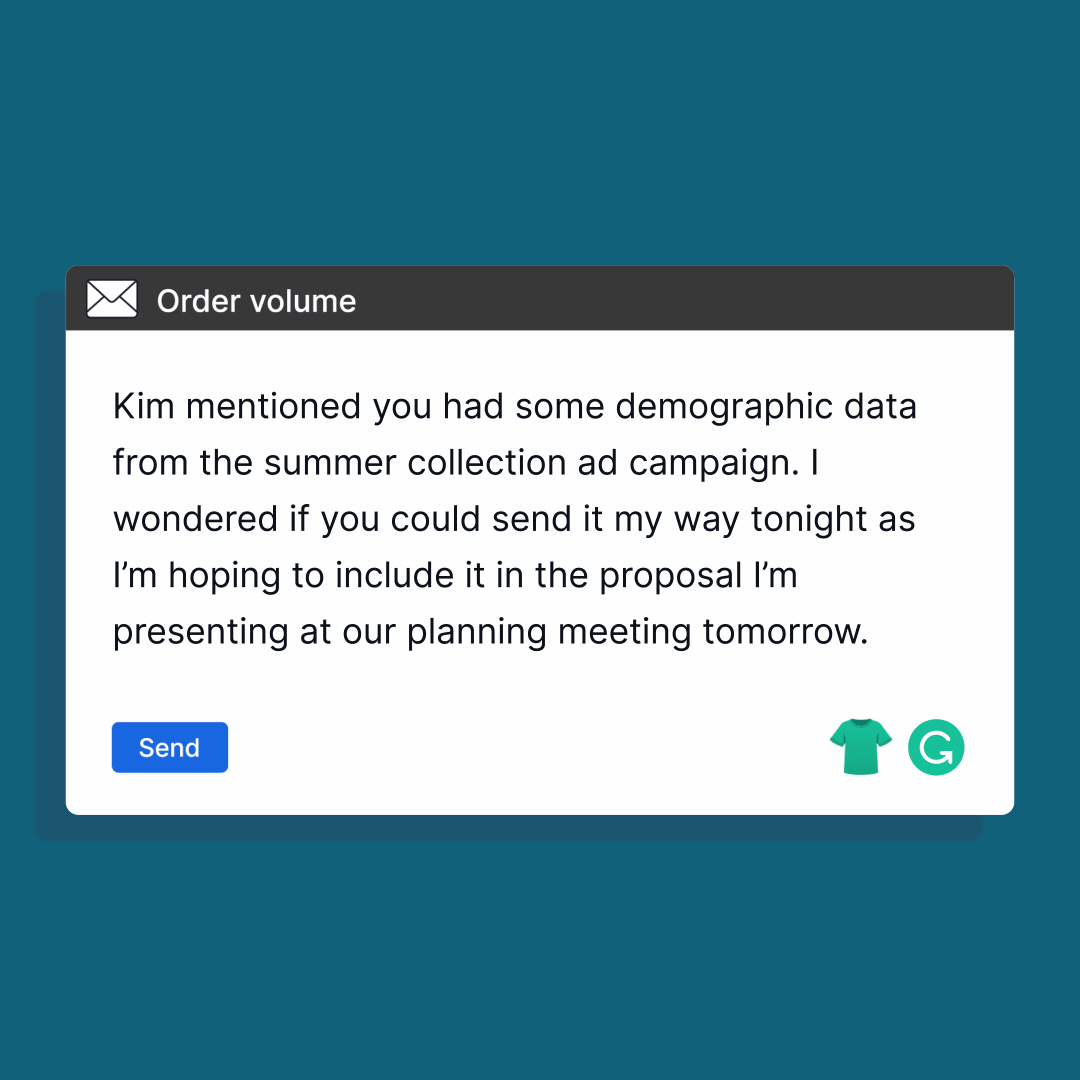
Image source: Grammerly
6. Text Classification
Text classification involves assigning predefined categories or labels to text based on its content. Language models, especially deep learning models like transformers, are used to build robust text classifiers. This is applied in spam detection, topic categorization, and sentiment analysis.
Example: Email providers like Gmail use language models to identify and filter out spam emails by analyzing the text content, ensuring that users receive relevant and non-malicious messages.
7. Dialog Systems and Creative Writing
Language models are employed in generating human-like text in conversational agents, chatbots, and creative writing applications. They can generate responses, stories, and even poetry.
Example: ChatGPT, powered by the GPT-3.5 architecture, is a language model designed for generating interactive and coherent conversations. It's used in applications ranging from customer support to interactive storytelling.
READ MORE: Top 17 Industry Applications of ChatGPT
8. Text Summarization:
Language models are employed in automatic text summarization to generate concise and coherent summaries of long pieces of text. This is valuable in applications where users need to quickly grasp the main points of a document without reading the entire content, such as news articles or research papers.
Example: Summarization API by Aylien offers an API for text summarization, allowing developers to integrate summarization capabilities into their applications, extracting essential information from lengthy articles.
Common Challenges in NLP Language Models
Language modeling in NLP faces several challenges, which researchers and practitioners have been working to address. Some of these challenges include:
1) Long-Term Dependency: Language models struggle with capturing relationships between words or phrases that are far apart in a sentence. Traditional recurrent neural networks (RNNs) face vanishing gradient problems, making it difficult to capture long-term dependencies. Although transformers have mitigated this to an extent, modeling very long sequences is still challenging.
For example: In the sentence "He said the bank on the river loaned him a pen," understanding the word "bank" requires knowing that it refers to a financial institution, which is evident from the distant word "loaned." Traditional models might struggle to establish this connection due to the sentence's length.
2) Low-Resource Languages: Many languages lack extensive textual data for training robust language models. Building effective models for these low-resource languages such as many indigenous languages, is challenging due to limited available data. This leads to poor performance in translation, sentiment analysis, and other language-related tasks for these languages.
3) Sarcasm and Irony: Detecting sarcasm and irony is complex because it often involves understanding not just the words but the underlying tone and context. Models often struggle to identify these nuances, impacting sentiment analysis and other tasks where understanding the speaker's intent is vital.
Example: In the sentence "Oh, great! Another Monday," the sentiment is negative despite the words being positive individually, making it challenging for models to recognize the intended sentiment correctly.
4) Handling Noisy Text: Real-world text data, especially from sources like social media, is noisy. It includes misspellings, grammatical errors, abbreviations, and non-standard language use. Language models need to be robust enough to handle such noisy inputs effectively.
Example: Social media posts often contain acronyms, misspellings, and informal language like "u" instead of "you." Understanding a sentence like "Thx 4 ur help!" requires the model to interpret abbreviations and misspellings accurately.
5) Contextual Ambiguity: Ambiguity is not just limited to individual words; entire sentences can be ambiguous based on context. Resolving these ambiguities requires understanding subtle contextual cues, making it challenging for language models to generate accurate interpretations.
Example: "I saw the man with the telescope." Does this mean the speaker used a telescope to see the man, or did the man have the telescope? Contextual cues are essential to resolving this ambiguity correctly.
How do You Plan to Use Language Models?
There are several innovative ways in which language models can support NLP tasks. If you have any idea in mind, then our AI experts can help you in creating language models for executing simple to complex NLP tasks. As a part of our AI application development services, we provide a free, no-obligation consultation session that allows our prospects to share their ideas with AI experts and talk about its execution.




