
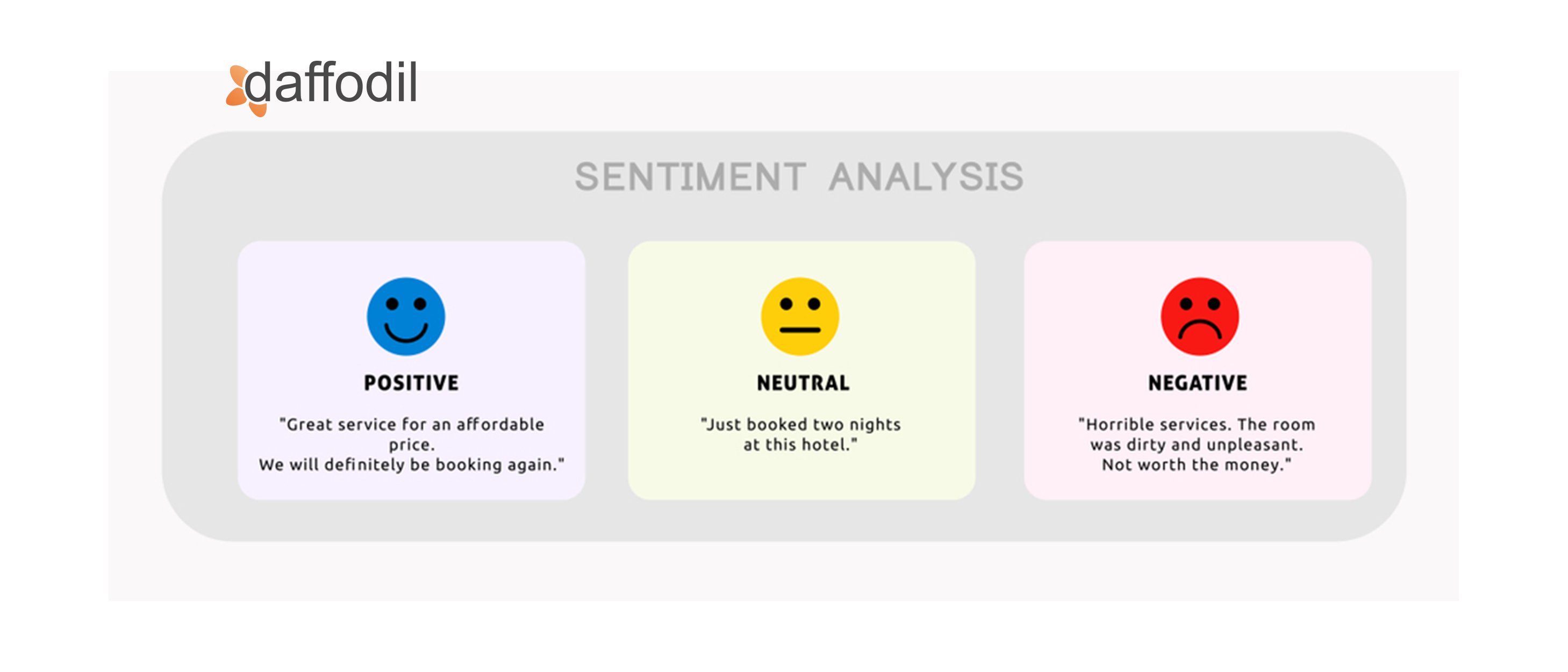
An essential component of textual and verbal data is context and understanding the context requires some amount of sentiment analysis. To comprehend and categorize subjective feelings from communications data, Natural Language Processing (NLP) and Machine Learning (ML) methods have been used in the past. Sentiment analysis is frequently used in professional settings to comprehend customer evaluations, identify email spam, etc.
As per a report compiled by nRoad, over 80% of all global data including user behavior, business workflows, logistics, economics, and so on is unstructured data. Making sense of all this data, especially user data requires special data engineering techniques including but not limited to sentiment analysis.
In this article, we will closely examine the entire sentiment analysis process from the data gathering stage all the way to the deployment of the analysis model.
What Is Sentiment Analysis In NLP?
Sentiment analysis is a process that employs statistics, NLP, and various ML strategies to parse the emotional context of textual, and verbal communications data. Organizations employ sentiment analysis to examine online comments, customer service interactions, social media posts, feedback, reviews, and so on.
By conducting drill-down sentiment analysis, enterprise-level changes in attitudes can be caught in time. If a company can identify the changes in the sentiments of their customer base towards their product or service offerings, they can make amends in time to attract and gain back interest.
The Sentiment Analysis Process
Companies use sentiment analysis to essentially examine whether their customers are comfortable or frustrated with the product or service offering that the latter is being provided. The sentiment analysis process consists of the following steps:
1)Web Scraping For Data
Web scraping is the practice of extracting data from websites as long as the websites permit it. Since most often the data that is scraped is unstructured, the web scraping workflow also involves the process of transforming the data into something that can be read and used. The basic three steps of web scraping include sending the request for the web page, followed by parsing the HTML response, and then locating the information we need and extracting it.
In order to extract useful information from the response from the server, we must parse the raw HTML and make it understandable by whatever programming languages you are using. Additionally, you must decide what kind of content you want to assess initially. In a movie review as opposed to an email, people express their emotions differently, and the context has an impact on process design.
2)Preprocessing Your Data Set
Features are not clearly available in text data, in contrast to structural data. So, in order to extract features from the text data, a method is required. To determine if a word is present or absent in a phrase, one approach is to view each word as a feature and develop a metric. The bag-of-words (BoW) model is used to describe this. Therefore, each sentence is viewed as a collection of words.
Each sentence is referred to as a document, and the corpus is the collection of all documents. A dictionary of all the terms used in the corpus must be created as the first stage in developing a Bow Model. Grammar is not important at this point; simply the word occurrences are being recorded. The words that are present in each document will then be converted into a vector.
3)Vectorized Transformation
Building a bridge between the information included in the text input and the machine learning models is what the transformation step does. The machine learning model for sentiment analysis must learn the sentiment score of each distinct word in the text and how frequently each word appears there in order to produce sentiment predictions for each document. For example, if we want to conduct sentiment analysis for customer reviews of a product, after training the model, the machine learning models are more than likely to pick up the words like “bad”, and “unsatisfied” from negative reviews, while getting words like “awesome”, “great” from positive reviews.
When faced with a supervised machine learning problem, we must provide the features and target values in order to train the model. Sentiment analysis is used to solve classification problems, typically binary classification problems with positive and negative goal values. Text data from a vectorizer that has been converted is used as one of the features in the model. Different vectorizers are used to create the features differently.
Customer Success Story: Daffodil helps a geospatial AI firm to map more than 30 cities by training machine learning models.
4)Building Sentiment Analysis Model
Here, you'll train an ML model to classify your content as positive, neutral, or negative using the testing dataset. The model architecture is left to you, although we advise training a verified, context-aware NLP model (like BERT). We also support using a transfer learning approach as opposed to creating a model from scratch. It would be ideal if you could start with a system that can read the text in your target languages (due to training on a large corpus of human language to create associations and knowledge of words and phrases).
Such a model can be improved for sentiment analysis tasks, and the outcomes will be far better than training a model from scratch. Word embeddings must be used to preprocess the text data as we work with it. The dataset for sentiment analysis contains more than 14,000 data samples. For this binary classification challenge, neutral reviews don't really need to be included in our dataset. Drop those rows from the dataset as a result.
5)Deploying The Model
You can now download a sizable dataset to experiment with; this dataset will be used to train and create your model. The dataset is then handled using a program called pandas. SentimentText was used as the predictor variable, with the column Sentiment set as 1 for positive emotion and 0 for negative sentiment. To turn the word streams into tiny tokens, import the ML model and spacy.
Fit the target and predictor variables into a pipeline made up of Hashingvectorizer and MultinomialNB. In order to use the trained model for apps, we may put it in a zip and dill file if we are happy with the model's accuracy. By avoiding the need to repeatedly retrain the model while uploading the entire dataset, this strategy can save a lot of time and space.
ALSO READ: What Is The Attention Mechanism In Deep Learning?
Provide Better Customer Service Leveraging Sentiment Analysis
Sentiment analysis aids in doing in-depth market research, understanding the strategies of your rivals, such as what customers appreciate about their offerings, and implementing best business practices. You have an advantage over your rivals because of this. To optimize the effectiveness of your customer service workflows, sentiment analysis is your best bet and if you are looking for a technology partner for this enablement you can book a free consultation with us today.



