

Custom user services are at the core of the success stories of a majority of internet companies like Netflix, Facebook, and Amazon today. This is why online platforms vying to stay at the pinnacle of their respective sectors need to build effective recommendation systems or recommendation engines.
Before the internet boom, recommendation-based initiatives were limited to attracting customers through word of mouth and through salespersons cold calling prospects directly. Today's recommendation systems employ algorithms and Machine Learning (ML) matrix manipulation and computational libraries.
As you read on, we will talk about what a recommendation engine really is and how they are built to provide customers with the most relevant content, products, and experiences in line with their particular preferences.
What Is A Recommendation Engine?
Put simply, a recommendation engine is a data filtering instrument that employs machine learning algorithms that studies a user's behavior to suggest the most relevant items to them. A consumer's behavior patterns are collected implicitly or explicitly and patterns in them are recognized.
Amazon presents its users with product recommendations using this kind of engine, while Netflix studies users' watch preferences to suggest relevant content to them. While all these platforms use recommendation engines towards varied ends, the overarching purpose is to drive up revenue by increasing user engagement and personalizing the user experience.
There are a number of types of recommendation engines, based on the type of data filtering that they do as described below:
1) Collaborative filtering: In order to forecast what a person will like based on their similarity to other users, data on user behavior, activities, and preferences are gathered and analyzed. Using a matrix-style method, collaborative filtering plots and calculates these similarities.
2) Content-based filtering: The idea behind content-based filtering is that if you enjoy one item, you'll probably enjoy this other one as well. Algorithms employ a description of an item and a profile of the customer's interests to determine how similar two things are using cosine and Euclidean distances.
3) Hybrid Model: This type of recommendation engine usually outperforms both the other types of engines by combining data around collaborative user preferences as well as the primary user's preferred content types.
Customer Success Story: How Daffodil helped India’s largest online merchandiser reduce 30% of manual analysis with automated reporting.
How Does A Recommendation Engine Work?
Recommendation engines work by feeding data through ML algorithms to develop a matrix of user preferences by cross-referencing similarities in search results. They basically take the user data through a sequence of the following steps:
1) Sampling
As data is at the center of the process, the first step is naturally the accumulation of user data. Two types of data are collected-
- Implicit Data comprises online user activity such as search history, online impressions, cart interactions, search log, and orders.
- Explicit Data consisting of active customer inputs in the form of reviews, feedback, testimonials, likes, and ratings.
Other types of data leveraged by the engines are demographics, psychographics, and feature data consisting of genre or item type to knit together product similarities.
2) Computing With Matrices
To form a recommendation, recommendation algorithms typically sift through a user's viewing history for overlap or co-occurrence. In real life, a recommendation engine creates a co-occurrence matrix from an event and action history matrix. Although this is rather straightforward, there are obstacles to overcome in practical situations.
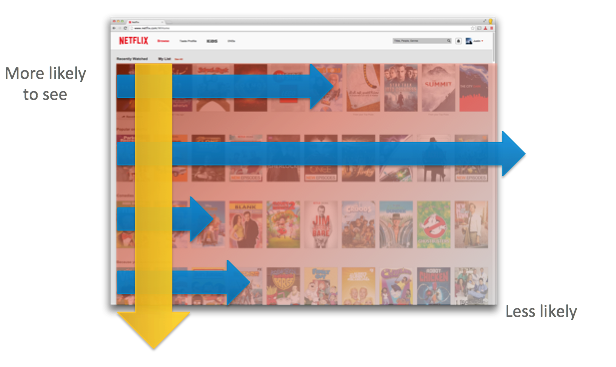
Image: Netflix Co-Occurrence Matrix
After the recommendation engine has calculated the co-occurrence matrix, we must use statistics to weed out signals that are too aberrant to be useful as recommendations.
3) Extracting Indicators
The more indicators the algorithm can extract from the co-occurrence matrices, the better the overall recommendation engine tends to be. Additionally, the engine must also pick out statistics about the user's preferences from the relevant indicators.
Item-item models are created, where the item is any product or content on the platform. User-item models are also created and using a simple matrix factorization, a neural network can predict what the user might like next. However, there must be nuances that can be improved upon so that the same recommendations are not presented to the user repeatedly.
4) Continuous Improvement
There are a variety of ways to introduce nuance in the recommendation engine so that the user does not get bored with the same type of content or product recommendations. A relevance score can be given to the produced results based on how much the user engages with the recommendations.
There are two ways of continuously improving upon the recommendation engine. Both these strategies are focused on maintaining a good relevance score by flattening out the fall in relevance over time. The improvement methods are as follows:
i) Anti-Flood: If the recommendations following the first recommendation have relevance scores similar to the first one, they must be penalized while giving the first recommendation nearly exclusive priority.
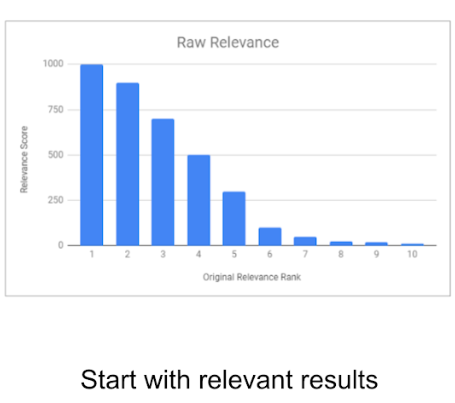
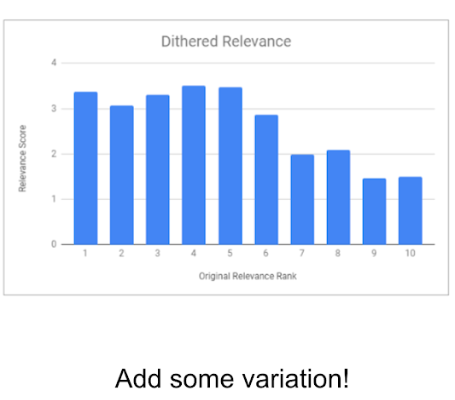
ii) Dithering: This is done to give the ML algorithm relevant data to keep learning about the user's preference over time. An unexpected recommendation is created as a test data point to allow the algorithm to go ahead and learn about other content outside the user's usual preferences.
Challenges Of Recommendation Engines
Large-scale online platforms thrive from expertly designed and well thought out recommendation engines. However, they benefit even more from understanding the various challenges that recommendation engines can face.
An in-depth view of these challenges can enable the development of recommendation engines that can yield more precise content and customer experiences. These challenges are listed below:
1) Semantic Redundancies
When a single product, piece of media, or item is listed under two or more names or categories that have similar meanings, such as an action movie or action film, the problem of synonymy develops. When this happens, the recommendation algorithm is unable to determine if the phrases display different items or the same item.
2) Scalability Limitations
The scalability of algorithms using real-world datasets is one of the supplemental problems with recommendation systems. Most often, the aggregation of items and clients has rendered the previous approach ineffective due to dataset difficulties and decreased performance.
3) Data Sparsity
Uninterested users often choose not to rate or review the things they buy, which results in a sparse rating and review model and difficulties with data sparsity. It leads to a higher likelihood of discovering a group of consumers with false comparable ratings or interests.
4) Privacy
Recommendation engines require a lot of data, and some of that tends to be extremely sensitive personal information. Algorithms tread a thin line but need access to this information to produce the most custom results specific to the user.
ALSO READ: Top 5 Data Science Trends For Businesses Today
Utilize Expert Data Engineering For Faster Recommendations
If faster time-to-market, reduced operational cost, and omnichannel experience for customers is the target of building your recommendation engine, then Daffodil’s Data Enrichment Services are the right choice for your needs.



