

Speech recognition is a technology that has been going through continuous innovation and improvements for almost half a century. It has led to several successful use cases in the form of voice assistants such as Alexa, Siri, etc., voice biometrics, official transcription software, and the list goes on. So what really is Automatic Speech Recognition and what are the underlying technologies that enable it?
Automatic Speech Recognition has been around since the Cold War era when the American Defense Advanced Research Projects Agency (DARPA) conducted research in human voice identification and interpretation in the 1950s. This was followed by several similar research projects leading up to the 1990s when the Wall Street Journal Speech Dataset was prepared.
Today Speech-to-Text and speech recognition see widespread application in a variety of consumer use cases, legal and corporate interpretation, and transcription. In this article, we will attempt to explain what are the technologies that make speech recognition work.
What Is Speech To Text?
Speech to text refers to a multipronged field of voice recognition software solutions that listen to a human voice, compare it with several manually trained voice-to-text databases, and synthesize it to finally convert it to text.
Leading global technology giants such as Google, IBM, and Amazon have been in the race for developing the most precise, fast, and accurate interpreter of the spoken voice for several decades now. Most recently, they have been figuring out the best way to combine computational linguistics and word processing with the use of Deep Learning, an advanced subfield of AI.
In addition to deep learning, speech recognition also leverages Big Data because big data's ability to store tons of data and make it easily searchable expedites the processing of several Yottabytes of audio recordings of the human voice.
Deep Learning Methods For Speech Recognition
AI and deep learning-based speech recognition software can be utilized for a variety of applications. These include transcribing legal depositions and educational dissertations, transcribing customer support conversations for gaining insights, building voice-based chatbots, and documentation of the minutes of a meeting.
While all sounds are composed of two elements; sounds and noises, human speech is a more complex example of sound as it contains intonations and rhythm with substantial innate meaning. Audio speech files are a form of encoded language that needs pre-processing.
The initial steps of speech to text are the following:
- The process of converting speech to text starts off with digitizing the sound.
- The audio data is then in a format that can be processed by a deep learning model.
- The processed audio is then converted to spectrograms, which represent sound frequencies pictorially so that each of the sound elements can be distinguished along with their harmonic structure.
- The spectrograms help in the audio classification, analysis, and representation of audio data.
These steps are followed by the audio classification, which involves dividing the sound into different classes and training the deep learning model on these classes. This allows the model to predict which class a given sound clip belongs to. So, a speech-to-text model takes in input features of a sound and correlates it to target labels:
- Input consists of spoken audio clips
- Target labels are text transcripts of the audio
Customer Success Story: How Daffodil developed an Automatic Speech Recognition Engine for a Legal Tech firm.
How Does Speech To Text Work?
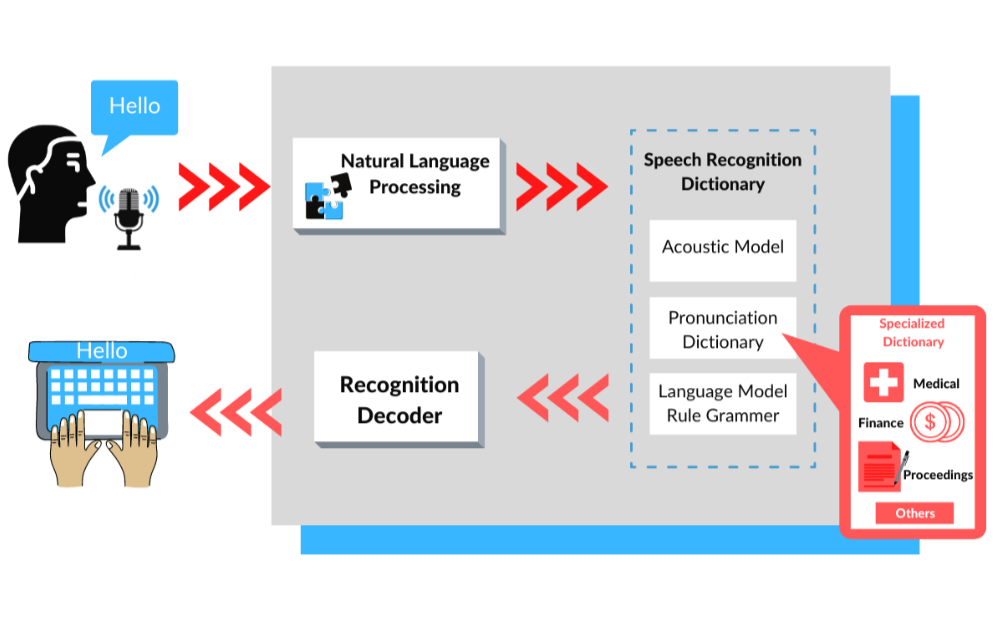
Broadly put, speech-to-text software listens and captures spoken audio as input and outputs a transcript that is as close to verbatim as possible. The underlying computer program or deep learning model utilizes linguistic algorithms that function on Unicode, the international software standard for handling text.
 Source: CCCI
Source: CCCI
The linguistic algorithms' basic function is to categorize the auditory signals of speech and convert them into Unicode. The complex deep learning model is based on different neural networks and converts the speech to text through the following steps:
1)Analog To Digital Conversion: When human beings utter words and make sounds, it creates different sequences of vibrations. A speech-to-text model would specifically pick up these vibrations which are technically analog signals. An analog to digital converter then takes these vibrations as input to convert to a digital language.
2)Filtering: The sounds picked up and digitized by the analog to digital converter are in a form that is machine-consumable as an audio file. The converter analyses the audio file comprehensively and measures the waves in great detail. An underlying algorithm then classifies the relevant sounds and filters them to pick up those sounds that can eventually be transcribed.
3)Segmentation: Segmentation is done on the basis of phonemes, which are linguistic devices that differentiate one word from another. This unit of sound is then compared against segmented words in the input audio for matching and predicting the possible transcriptions. There are approximately 40 phonemes in the English language and similarly, there are thousands of other phonemes across all the languages.
4)Character Integration: The speech-to-text software consists of a mathematical model consisting of various permutations and combinations of words, phrases, and sentences. The phonemes pass through a network consisting of elements of the mathematical model so that the most commonly occurring elements are compared to these phonemes. The likelihood of the probable textual output is calculated at this stage for integrating the segments into coherent phrases or segments.
5)Final Transcript: The audio's most likely transcript is presented as text at the end of this process based on deep learning predictive modeling. A computer-based demand generated from the above probabilities is then produced from the built-in dictation capabilities of the device that is being used for transcription.
ALSO READ: Why Machine Translation In NLP Is Essential For International Business?
Increase Transcription Accuracy With Custom Speech-To-Text Solutions
Several benefits of speech-to-text ease plenty of daily operations across industries. By providing meticulous transcripts in real-time, automatic speech recognition technology lessens processing timespans. With speech-to-text capacities, audio and video data can be converted in real-time for quick video transcription and subtitling. More competent software built using AI and machine learning is required if you want to convert a lot of audio to text and Daffodil's AI Development solutions.



