The proliferation of digital transformation has made system reliability an essential component of any organization's bottom line. These rapid changes have become a new benchmark for success and efficient incident response is key in sustaining site reliability through these changes.
Tech giants like Amazon, Alibaba Group, and many more, deal with millions of customer interactions and online business transactions all the time therefore, even a momentary system downtime could cost them billions. With such a large amount of money and data at stake, neither enterprises nor customers can bear any error or disruption in their online business exchanges. So how do we prevent, minimize, and eliminate these errors if it occurs? This is where Site Reliability Engineering (SRE) comes into the equation.
SRE is a revolutionary new approach to systems management and has completely changed how organizations look at release velocity, incident response, reliability, and management. SRE adoption has acted as a catalyst in an organizational cultural shift, a shift which is transforming how enterprises are structured, on how data flows within an enterprise that would allow for the delivery of more reliable, flexible, and dynamic systems.
By utilizing the key principles of site reliability engineering in IT operations, organizations can build systems that are more reliable, efficient, and responsive to customer requirements. In addition, SRE can help to identify and fix issues before they cause disruptions or downtime. As a result, SRE has become an effective approach to managing IT infrastructure and services. In this blog, we’ll look at what SRE is, its origin and best practices, and how it can benefit your organization.
What is Site Reliability Engineering?
Site reliability engineering is a discipline that covers a set of principles, practices, tools, and cultural philosophies to solve IT infrastructure and operational problems. It depicts the solution between what actually occurs in the application and what we want to happen to guarantee an exceptional user experience.
SRE is focused on automating and monitoring processes over manual control and aims to prohibit outages and system downtime rather than simply reacting to them after the fact. As such, SRE teams are responsible for assuring that systems are meeting availability Service Level Agreements (SLA), while also continuously increasing efficiency and performance. In addition, SRE teams often work closely with other software engineering teams to develop new features and products in a way that doesn’t sacrifice reliability.
The end goal is to improve the reliability of the services. According to Google SRE's book, “Reliability” is described as a subjective metric, indicating not just the availability of services, but how useful they are to users.
Furthermore, the concept of DevOps has brought engineering and operations functions together with a common methodology and shared result— to ensure service reliability and availability after deployment — with the SRE acting as the bridge between the two functions. In other words, SRE helps in implementing successful DevOps practices.
It combines software engineering and operations to build, deploy, monitor, and maintain those systems that are both highly reliable and scalable and also emphasize on improving customer experience.
According to Google, the Key Principles of SRE are:
- Embracing risk: It offers neutral approaches to service management using error budgets.
- Service level objectives: It provides recommendations for disentangling indicators from agreements, examines how SRE uses the terms, and helps in finding useful metrics for your own applications.
- Eliminating toil: It's about stepping away from mundane and repetitive operational tasks that hold null value to service growth.
- Monitoring distributed systems: For high reliability of the service, always monitor what is going on in the organization.
- Release engineering: To ensure stability in your services, carefully track all the releases for consistency and prevent outages with continuous release engineering.
- Simplicity: Simplicity means building the least complex system that still performs as intended. It is easier to monitor, restore, repair, and improve the simpler system.
Customer’s Success Story: Read how Daffodil ensures 99.9% of system uptime for a public transport tracking application.
The Origin of SRE
Site Reliability Engineering (SRE) was first introduced by Google in 2003. Before SRE Google used a system administrator or sysadmin approach to carry out its IT operations. System Administrators handled the operations aspects, while software engineers worked on the development side.
However, because of different backgrounds, skills, and different perspectives, this approach created a conflict between the two groups. Operations team, who were concerned about ensuring the efficiency, availability, and reliability of software applications while developers were only concerned about releasing new features and rapid changes as soon as they are ready for a rollout.
Ben Treynor, who is the founder of the term SRE aptly describes it as “what happens when a software engineer is tasked with what used to be called operations”.
In an interview, he further elaborated:
“Fundamentally, it’s what happens when you ask a software engineer to design an operations function…So SRE is fundamentally doing work that has historically been done by an operations team, but using engineers with software expertise, and banking on the fact that these engineers are inherently both predisposed to, and have the ability to, substitute automation for human labor.”
In order to ensure that Google services were accessible, available, dependable, and highly reliable, SRE got introduced. The SRE concept was created to manage all complex operations to be resolved by technically feasible solutions. SRE acted as a bridge to overcome the gap created between the ops and devs teams. The ultimate purpose of SRE is to build and support scalable and highly reliable software systems.
What are the Key Practices in Site Reliability Engineering?
Adopting SRE best practices take time and effort to actively monitor your team's progress and systems for better performance and system reliability concerns. But, in the end, It will help in removing silos and strengthen the bond between the Development and Operations team.
Below are the SRE practices that can be grouped into five core categories:
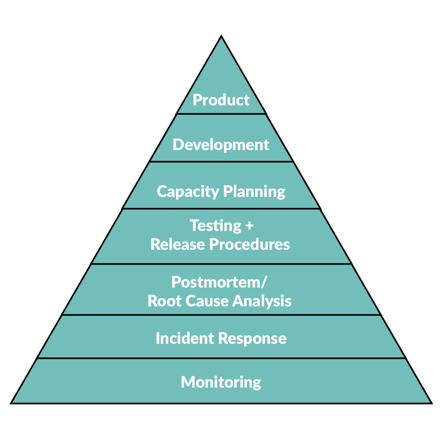
1. Monitoring: System health analysis— One of the SRE's biggest challenges can be overcome with effective monitoring. SRE teams implement appropriate monitoring solutions based on how the respective services measure availability and performance and provide a holistic view of system health before the end user notices any error.
2. Incident Response: It allows SRE teams to respond, review, and manage any incidents that occur within the system and helps them in restoring the service to its previous condition. This process includes an on-call playbook to guide those responses to an event. It also offers blameless post-mortems to understand what caused a particular problem and how to prevent it from happening again.
3. Postmortem/Root Cause Analysis: A postmortem (or Root Cause Analysis) is a process planned to help you learn from past incidents. It is a written record of an incident, the root causes, its effect, the measures taken to resolve the issue, and the follow-up analysis and measures to prevent the incident from recurring.
A well-designed, blameless postmortem allows teams to build a culture of learning and identifies opportunities to iteratively improve your infrastructure and incident response process.
4. Testing + Release Procedures: After forming an understanding of what went wrong, the next step is to prevent it from happening again. SRE teams use various test suites, find reliable solutions, and test them before releasing them to production.
5. Capacity Planning: Capacity planning is a vital metric that estimates the storage amount of each resource that is needed to sustain the service. It makes sure that given services have enough spare capacity to handle any likely increases in workload between planning iterations. It helps organizations plan their services and applications according to the customers' demands.
For instance, you may estimate how much storage you will need for the next five months, which is capacity planning.
6. Development: The integration of site reliability engineering into development and IT allows developers to get more involved in the production environment and helps IT operation teams to learn more about the development life cycle. As a result, the output is a more proactive and responsive approach to reliability concerns.
7. Product: The topmost component of the reliability pyramid, indicates that a product is workable and ready to be launched for the users to experience the best quality of services.
What are the “Four Golden Signals” of SRE?
SRE practices deliver visibility and transparency across all services and applications within a distributed system. But measuring the reliability, availability, and performance of disparate systems in these environments is complex. To make the practice simpler, Google’s SRE team introduced the four golden signals, an effective framework to identify the service health of the distributed systems.
To measure the criteria for the health of services, Steve Mushero summarizes this framework that includes:
1. Latency: This is the time taken to respond to a request, including queue/wait time, in milliseconds. Good latency rates should always be at or below a given threshold. By tracking latency across the whole distributed system, SRE teams can gain insights into services that are underperforming and can detect incidents as well.
2. Traffic: It measures the number of users or transactions that the system is taking at a given time. With this metric, SRE teams monitor the traffic and real-time user interactions with the product and also analyze their experience. It also helps in evaluating how new features have impacted the target audience as well as the system.
3. Errors: This metric indicates the rate at which requests fail. SRE teams have to track the number of errors occurring across the whole system, create an error budget, evaluate which errors are most acute and respond quickly to fix frequent errors.
4. Saturation: It provides visibility to the SRE teams of a given service by revealing the overall capacity of the system and the resources it has available so that they can set a benchmark for a “healthy” percentage of resource utilization. Thus, It helps in ensuring service performance and availability for customers.
Read Also: How SRE is Different from DevOps?
What are the Benefits of Site Reliability Engineering?
Site reliability engineering delivers astute customer experience by ensuring the reliability and availability of software applications resulting in several other benefits as well, including:
1. Increases Observability into the System:
SRE teams are connected with not only the DevOps team but various other different areas of an enterprise’s systems as well, which provides them insights into how those systems are coupled and how they work together. SRE helps in creating a holistic view of overall system health using metrics across many disparate services and detecting issues. As a result, these issues come to the surface and help teams to address the problem beforehand in the product roadmap.
2. Better Communication Between Developers and Operations:
SRE helps in building a stronger bond between developers and ITOps by breaking down the barriers using automation and improving communication that benefits both teams. It shows weaknesses in the release pipeline that aids in ensuring on-call availability and incident response. Hence, it helps improve and enforce best practices and supports inter-departmental resilience across the organization as well.
3. Infrastructure modernization:
Network Operations Centers (NOC) have commonly relied heavily on repetitive manual labor for triaging incidents and signals and evaluating how to redirect them to the right person. SRE streamlines these processes with automation and monitoring tools, identifies the effective way to route alerts through systems, and enables alerts to be automatically redirected to the person responsible for fixing the issue.
Make reliability a core feature of your software development for better coherence
The SRE model has caused a significant change in how organizational leaders deduce operational roles and practices in software engineering. Conventionally, business stakeholders only valued the development of new features in software applications and inherent IT operations and other activities were treated as an unreasonable expense. But with SRE implementation, business leaders have perceived that the complete software solution, throughout the different phases of its development lifecycle, needs to be considered and valued accordingly.
SRE has broken down the barriers between software development and IT operations, as well as has enhanced DevOps-based strategies. SRE empowers these two teams to focus on building innovative solutions rather than putting out fires all the time. As a consequence, software developers are emboldened to embrace risk in their work, which conclusively leads to long-term success for enterprises. Therefore, organizations that embrace SRE inevitably reap its many advantages for assistance in achieving system sustainability and growth.
If you want a technology partner to leverage the benefits of SRE in your infrastructure then Daffodil’s IT-managed service is the right solution that will help you to achieve high reliability and scalability for your software applications.