

Conversational systems that leverage Artificial Intelligence (AI) have helped automate a wide range of business processes, especially those involving interactions with the customer. Natural Language Processing (NLP) comes into play for a majority of these processes, but it is often hindered by functional hurdles. Reinforcement learning is a method for navigating these hurdles to make NLP-driven business processes more seamless.
Reinforcement learning is highly advantageous and well-suited to solve a variety of business problems focusing on conversational systems. Various scientific research papers have proposed an array of applications of reinforcement training models in NLP. Sometimes a combination of supervised and reinforcement
This article will begin by decoding what reinforcement learning is and how it works. It will then attempt to explain the most widely recognized NLP-based applications of this AI training method.
What is Reinforcement Learning?
Reinforcement learning is a sub-domain of machine learning that deals with training AI models to yield the maximum reward possible from a process or task assigned to them. The most optimal path or behavior is encouraged in the AI model by giving it negative inputs every time it causes the undesired outcome from a task. AI-based reinforcement learning derives its fundamentals from human psychology research, wherein good behavior is rewarded and bad behavior patterns are punished.
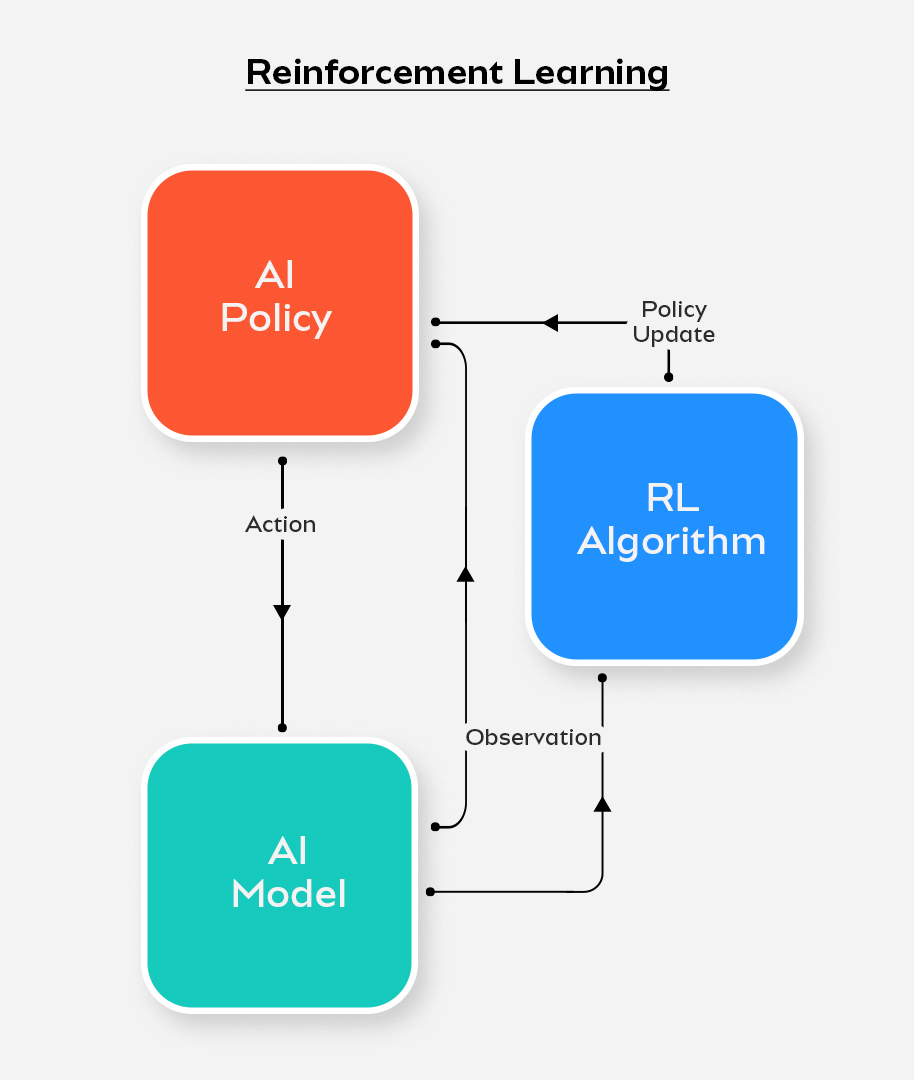
In the diagram given above, we assume that the main agent committing the action is an AI model. Actions are performed based on a list of norms pre-programmed into the AI model which we can refer to as the 'policy'. When a reinforcement learning algorithm is introduced into the natural flow of an AI task, it changes certain things.
Every time an action is performed, based on the outcome, the algorithm decides whether to make changes in the underlying policy. When the outcome is as desired, the policy remains unchanged, but otherwise, a policy update takes place via the reinforcement learning algorithm. After the policy is updated, the AI model performs the same action differently and this goes on until the most optimal outcome is achieved repeatedly.

Top 6 NLP Applications Of Reinforcement Learning
Reinforcement learning enables the AI model to learn the best behavior that would maximize the possibility of a positive outcome through rewards. Feedback from the AI model's environment helps it learn what should ideally be the most rewarding behavior patterns.
Several research papers demonstrate how deep reinforcement learning algorithms can be applied to real-world NLP problems. Some of the applications of reinforcement learning in NLP are explained below:
1)Policy Learning
Reinforcement learning systems can train healthcare software policies to enhance patient outcomes. This is done by finding the optimal policies based on previous experiences without having to manually add information from the previous patient interactions into the system. This is a step above the traditionally used control-based systems in healthcare.
Reinforcement learning algorithms are given controlled access to policies formulated by authorities that are stored in cloud repositories. While supervised learning-based NLP can read through these policy documents, it is reinforcement learning that actually trains an AI model to sift through terabytes of documentation to find the most effective policies. These policies vary across departments of dynamic treatment regimes, general physician domains, chronic disease, and even critical or palliative care delivery.
2)Dialogue Generation
Chatbots can be trained for optimized customer outcomes through the application of reinforcement learning in dialogue generation. Future rewards are modeled in a chatbot dialogue through a sequence of reward-based training iterations. Two virtual entities are designed and conversations are held between them to formulate the best customer-centric results from them.
Important conversation attributes such as ease of answering, degree of semantic coherence, and the grade of informativity are maximized through reinforcement learning algorithms. Policy gradient reinforcement methods are applied to NLP models that are trained on end-to-end conversations between AI entities.
3)Machine Translation
Machine translation, better known as neural machine translation in the deep learning paradigm, is a method that uses reinforcement learning to form conditional word distributions from a given text. This is essential to translate between drastically different languages such as the verb-final German to the verb-medial English language. Machine translation is supposed to translate in real-time as and when it receives each word of the input text.
In machine translation, the AI model must wait for the source text to appear before translation begins. Reinforcement learning equips the machine translation AI model to know when to pick a word from a stream of input and when to wait for more input. It can also help make accurate predictions about unseen, future portions of the incoming text. It outperforms batch and monotone translation methods in terms of quality as well as effectiveness.
Simultaneous translation finds its use predominantly in diplomatic settings, where the quality of international relations depends on the quality of translation. Reinforcement learning strategies help resolve the issue of information coming early in the target language but coming late in the source language. This it does by adjusting for latency without making a tradeoff in terms of accuracy.
4)Abstractive Text Summarization
Very lengthy documents often need to be shortened into more manageable summaries that include all the essential components, which is a tedious task when done manually. Attentional, RNN-based encoders seem to solve the problem up until a certain length of documents. Instead, a reinforcement learning-based AI model can employ a neural network with a novel intra-attention.
What this type of AI model does is that it attends over the input and spontaneously generates the abstract text summarization. It is often combined with a supervised word prediction model to optimize the resulting accuracy of the documentation summaries.
5)Question Answering
When question answering tasks come under the paradigm of reinforcement learning strategies, they become active question answering. NLP systems that are built to do so are trained to reformulate questions to elicit the best possible answers. Through reinforcement learning, the system examines several NLP-based reformulations of an initial question and aggregates the optimal answer.
The answer quality is maximized through end-to-end training using a policy gradient based on a dataset of complex questions. Other reinforcement learning-related benchmarks such as the role of the environment, the agent, and the action are put through a question-answer loop to learn to produce a standard set of answers.
Sentiment analysis focuses on deciphering the emotional tone expressed within text data. It plays a crucial role in understanding whether a piece of text conveys a positive, negative, or neutral sentiment, and to what extent. This process is particularly beneficial in various industries, including marketing, customer service, finance, and social media monitoring, as it offers insights into public opinion, customer feedback, and market trends.
Now, you might wonder, where does RL come into play in sentiment analysis? Reinforcement learning complements sentiment analysis by aiding in the continuous improvement of sentiment classification models. These models learn and adapt from their interactions and experiences, and reinforcement learning provides a mechanism to enhance their accuracy and effectiveness.
In this setup, the model is exposed to text data (such as customer reviews or social media comments) and provides feedback on its sentiment predictions. For instance, if the model incorrectly identifies a negative sentiment as positive, it learns from this mistake and adjusts its algorithms to avoid similar errors. This iterative learning process allows the model to become more proficient over time, making it better at classifying sentiments accurately. It fine-tunes its understanding of language nuances, context, and even sarcasm, thereby improving its overall performance.
ALSO READ: What are Language Models in NLP?
What is Deep Reinforcement Learning?
Deep reinforcement learning (Deep RL) is a branch of artificial intelligence (AI) that combines two powerful techniques: deep learning and reinforcement learning. We already know what RL means, so let’s dive into deep learning:
Deep learning involves using artificial neural networks, which are computational structures inspired by the human brain, to process and analyze data. These neural networks are especially effective at handling complex and high-dimensional data, such as images, audio, text, and more. Deep learning has transformed many areas of AI by enabling machines to automatically learn and represent intricate patterns in data.
Now, let’s bring these concepts together:
In Deep RL, neural networks (the "deep" part) are used to approximate and improve the agent's policy. The agent learns to make better decisions by analyzing the environment's feedback (rewards or penalties) and adjusting its actions accordingly. This is achieved through a combination of deep neural networks, which can handle complex sensory input, and the principles of reinforcement learning, where the agent learns from experience.
Deep reinforcement learning has proven to be exceptionally powerful in solving complex problems across various domains. It is used in robotics for tasks like autonomous navigation, in gaming for playing complex games like chess and Go, in natural language processing for tasks like dialogue generation, and in many other fields where intelligent decision-making is required.
Real-Life Use Cases of RL in Enhancing NLP Tasks
1) Example: Amazon's Alexa for Business
Use Case: In the corporate world, Alexa for Business is used as a virtual assistant to streamline office tasks. It employs reinforcement learning to optimize meeting scheduling, room reservations, and task automation. For instance, it learns to schedule meetings at times that are most convenient for team members based on their previous interactions. It adapts to changing office dynamics, ensuring smoother and more efficient work processes.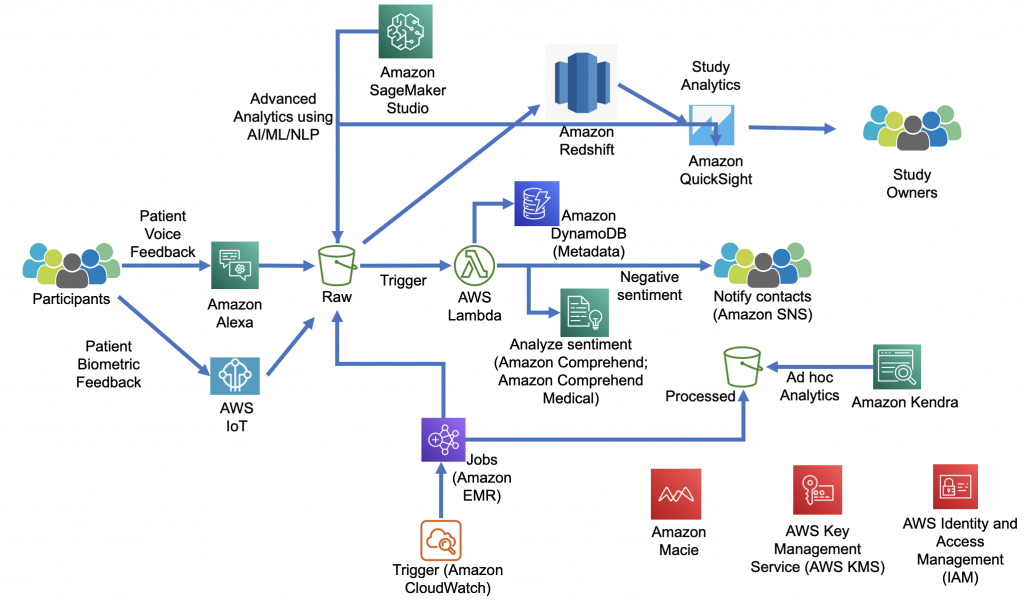
Image source: Amazon AWS
Customer Success Story: Developing a voice-first super application for a US-based AI technology company
2) Example: Google's Gmail
Use Case: Gmail, one of the world's most widely used email services, utilizes reinforcement learning to combat spam. The system continuously learns from user actions, such as marking emails as spam or not spam, and uses this feedback to improve its ability to identify and categorize unwanted emails. By adapting to evolving spam techniques, Gmail's spam filter remains effective in blocking unwanted content and keeping users' inboxes clean.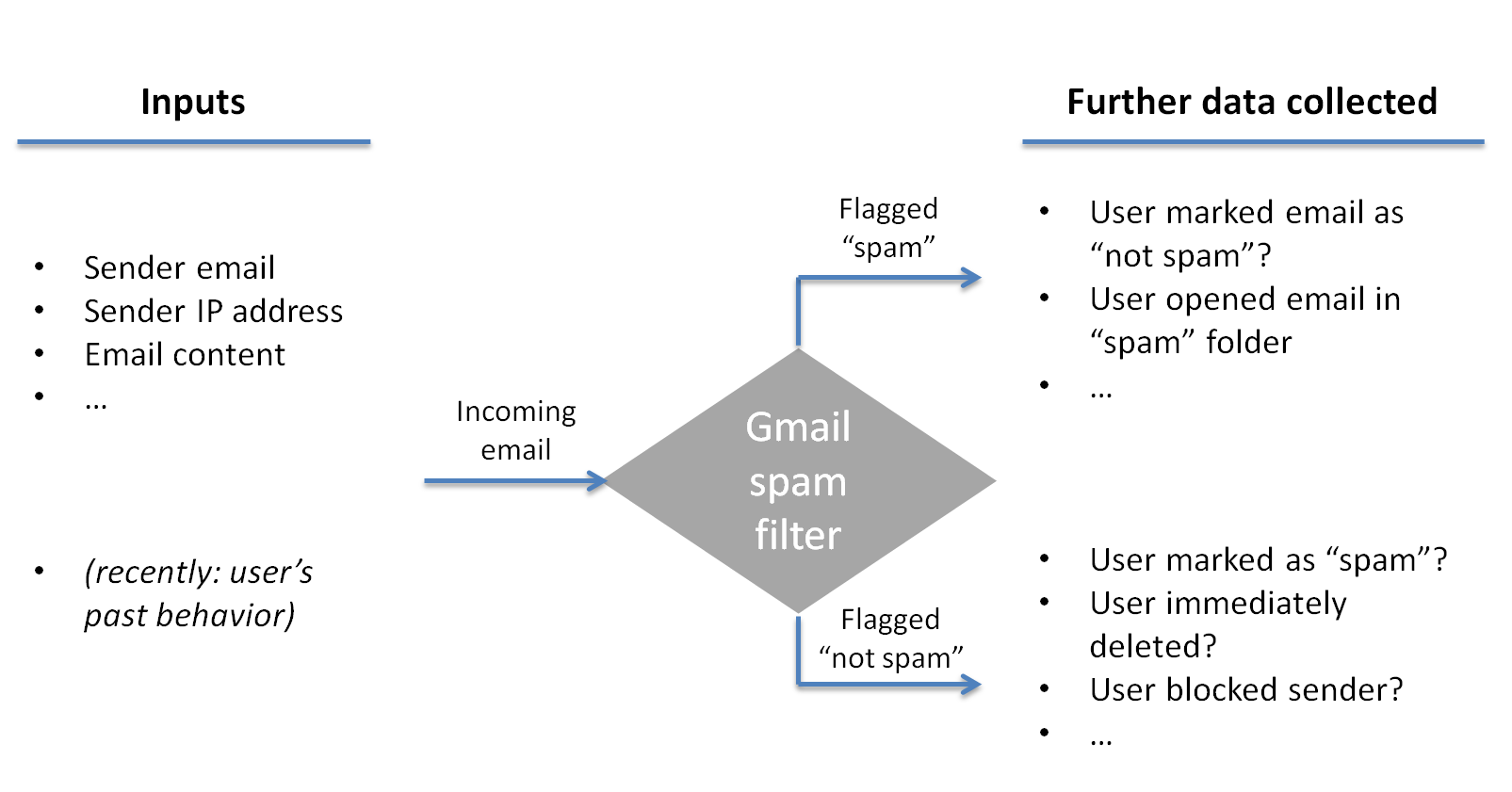
Image source: Harvard
3) Example: Grammarly
Use Case: Grammarly is a popular writing assistant that employs reinforcement learning to enhance users' writing. It goes beyond basic spell-check and grammar correction, providing real-time suggestions for improving writing style, clarity, and tone. The RL model learns from millions of users who make corrections and accept or reject suggestions. Over time, it becomes increasingly adept at helping users compose clear and engaging content, making it a valuable tool for writers, students, and professionals.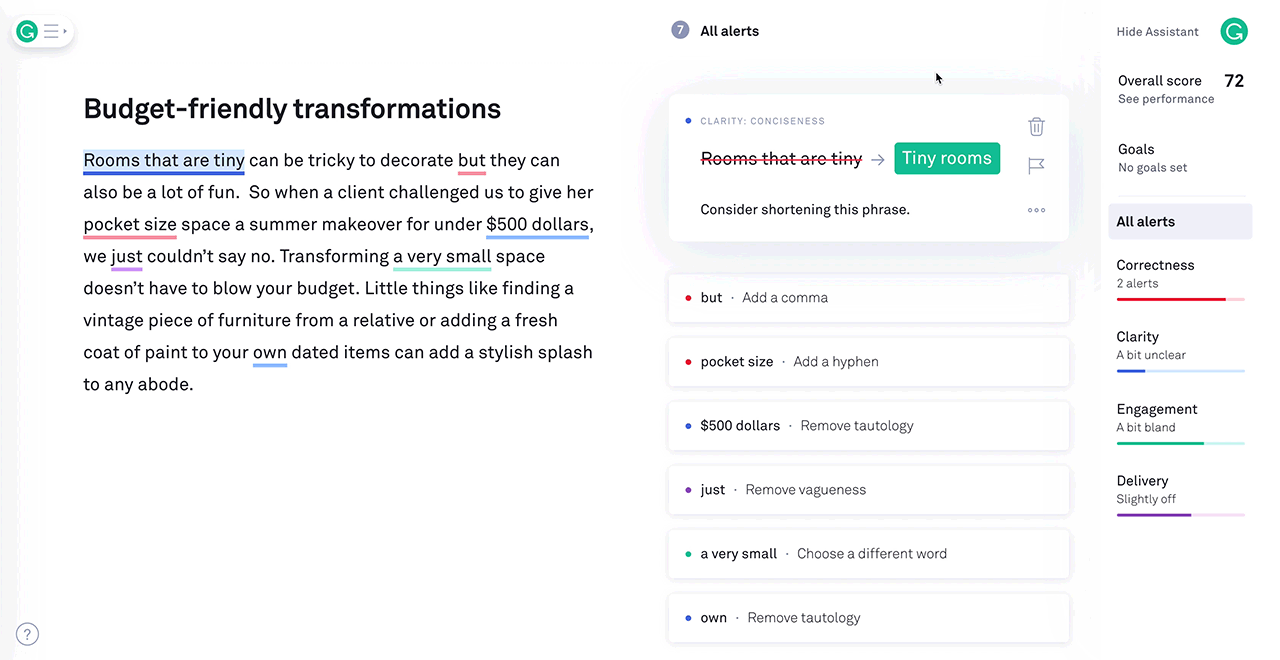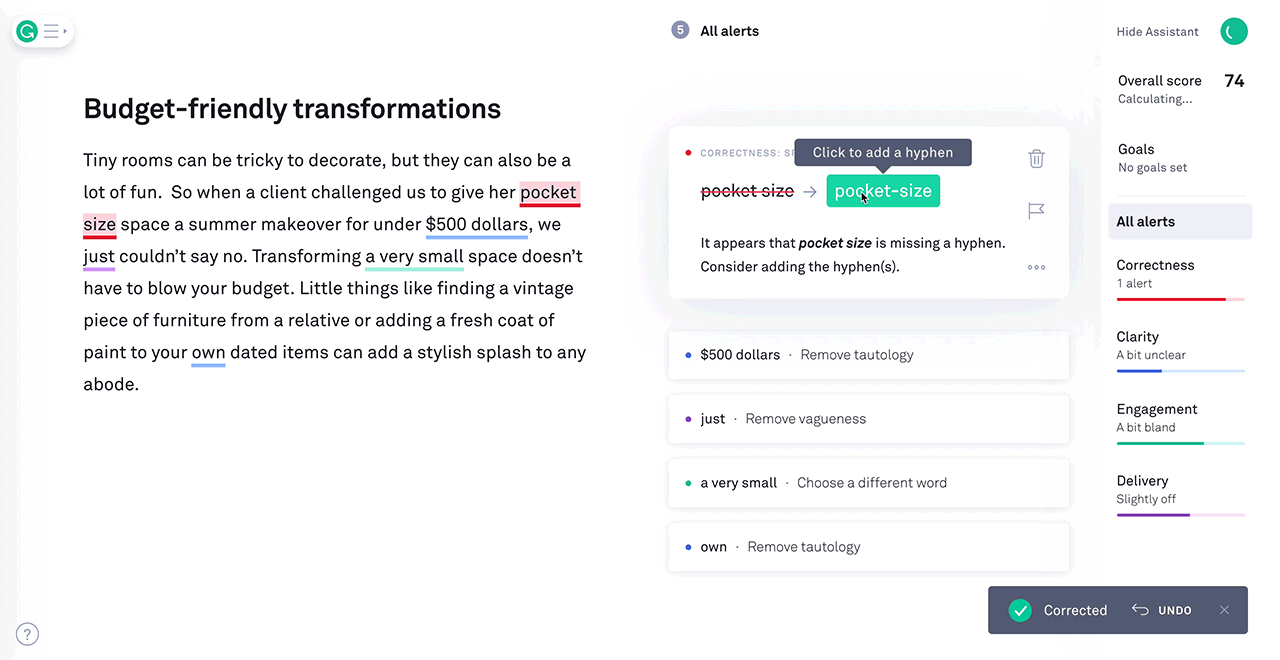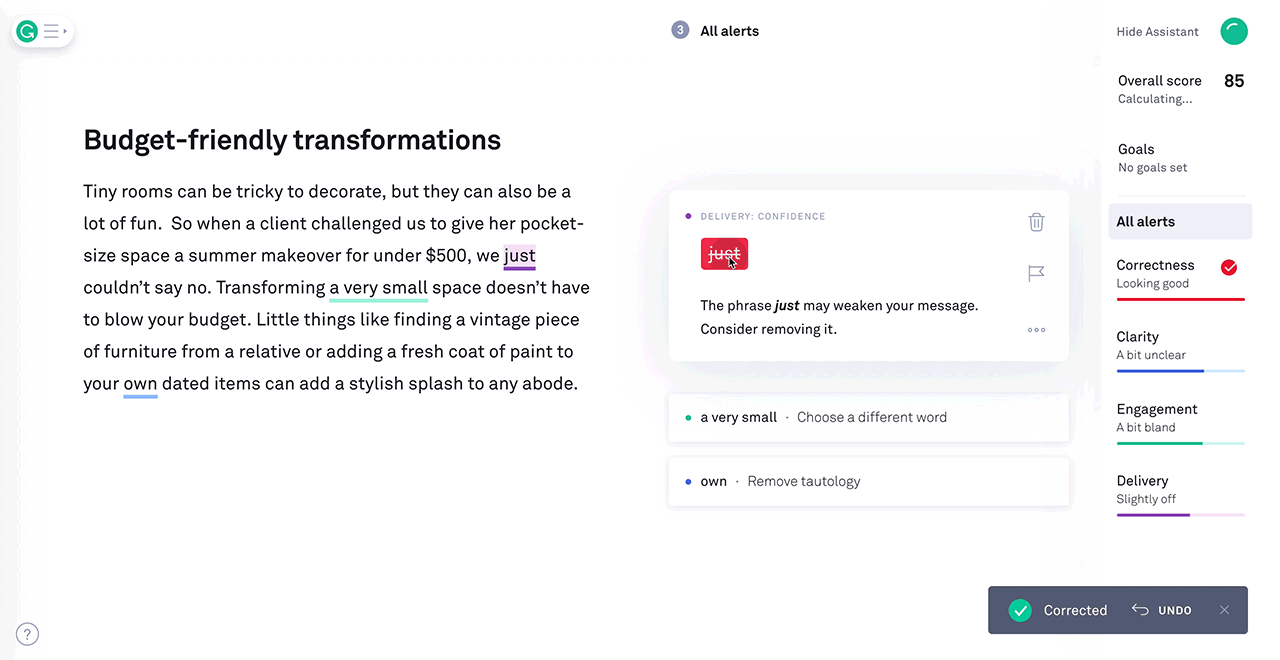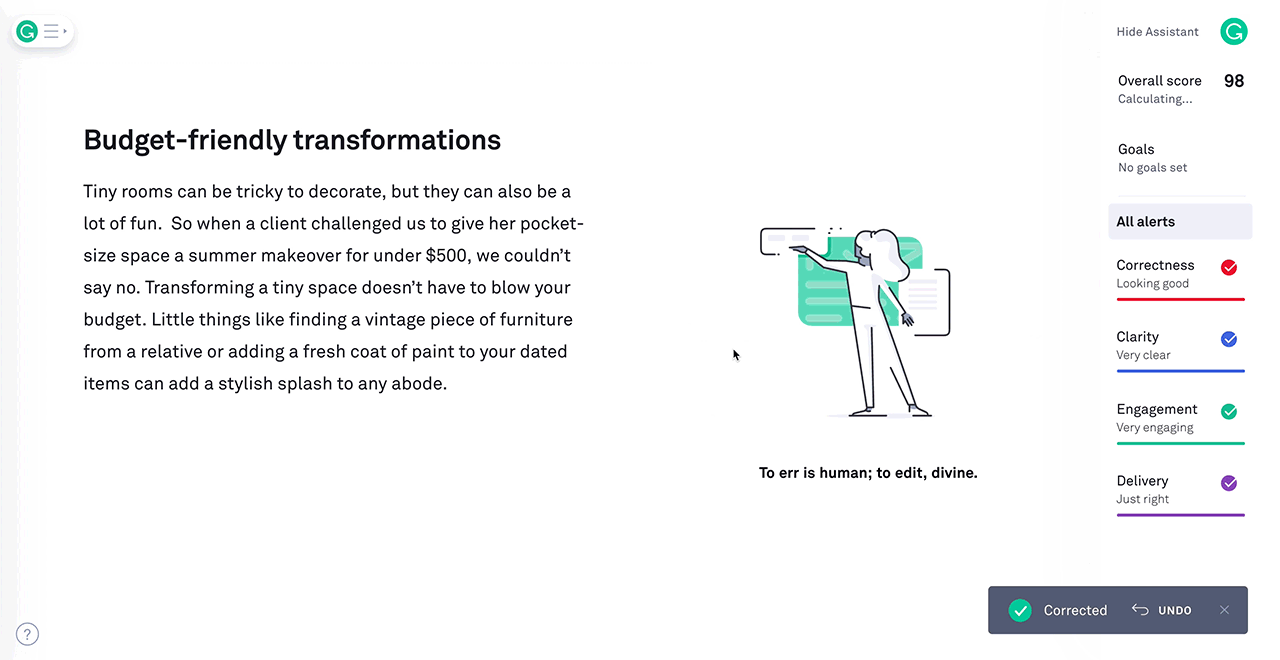
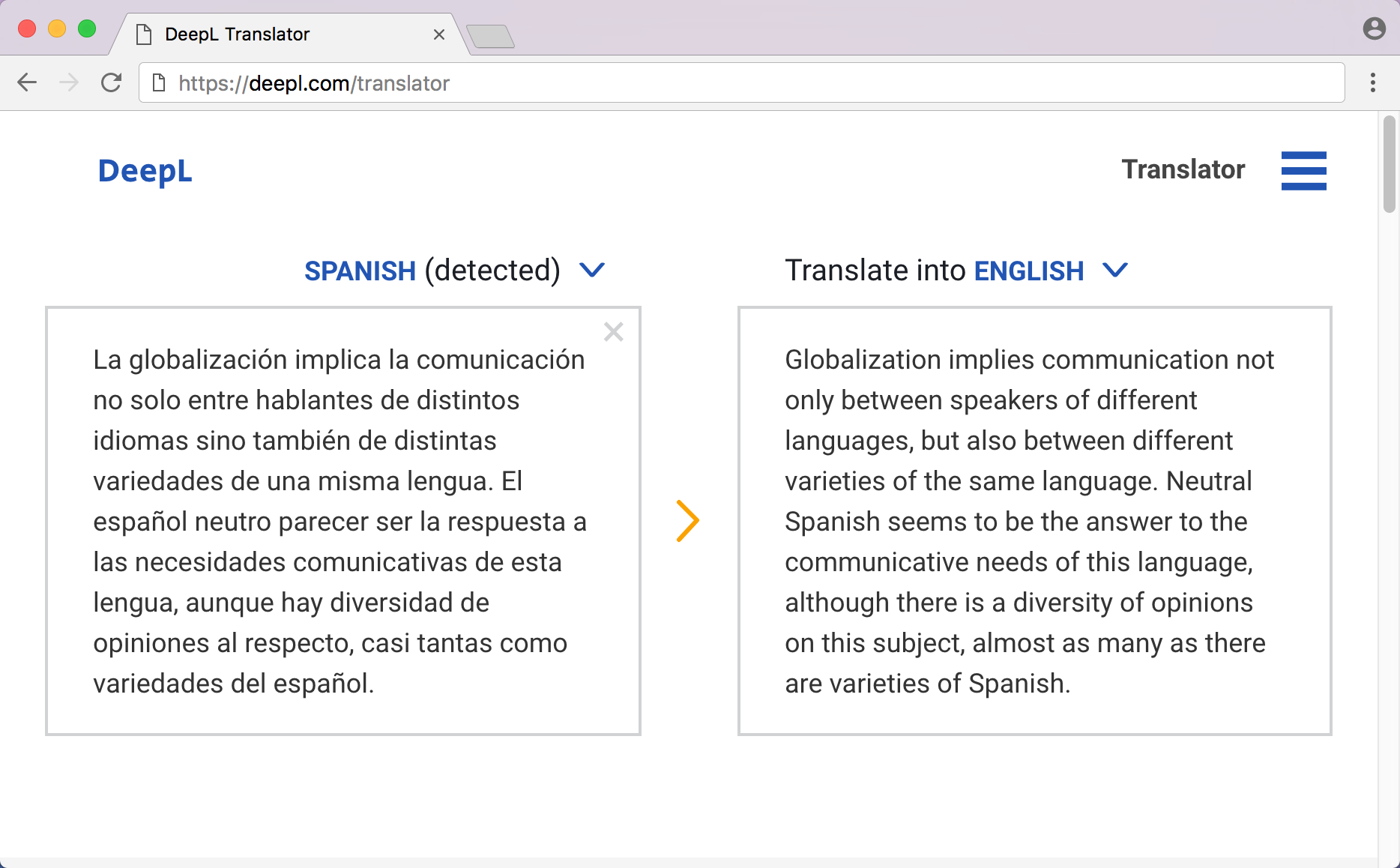
4) Example: DeepL Translator
Use Case: DeepL Translator is an advanced machine translation service that leverages reinforcement learning to offer highly accurate translations. It learns from extensive parallel text data and user interactions to refine its translation models. For example, if a user frequently selects a certain translation suggestion over others for specific phrases, the system adapts to prioritize that choice in similar contexts. This ensures that translations are not only linguistically correct but also contextually relevant.
5) Example: Netflix
Use Case: Netflix is a prime example of how reinforcement learning can transform content recommendations. It continually analyzes user viewing habits, interactions, and preferences to provide personalized movie and TV show suggestions. The RL algorithms strike a balance between exploring new content recommendations and exploiting known user preferences. For instance, if a user enjoys watching thrillers, the system will suggest new thriller releases while also introducing them to other genres based on their evolving tastes. This personalized recommendation system keeps viewers engaged and satisfied, leading to increased user retention and engagement on the platform.
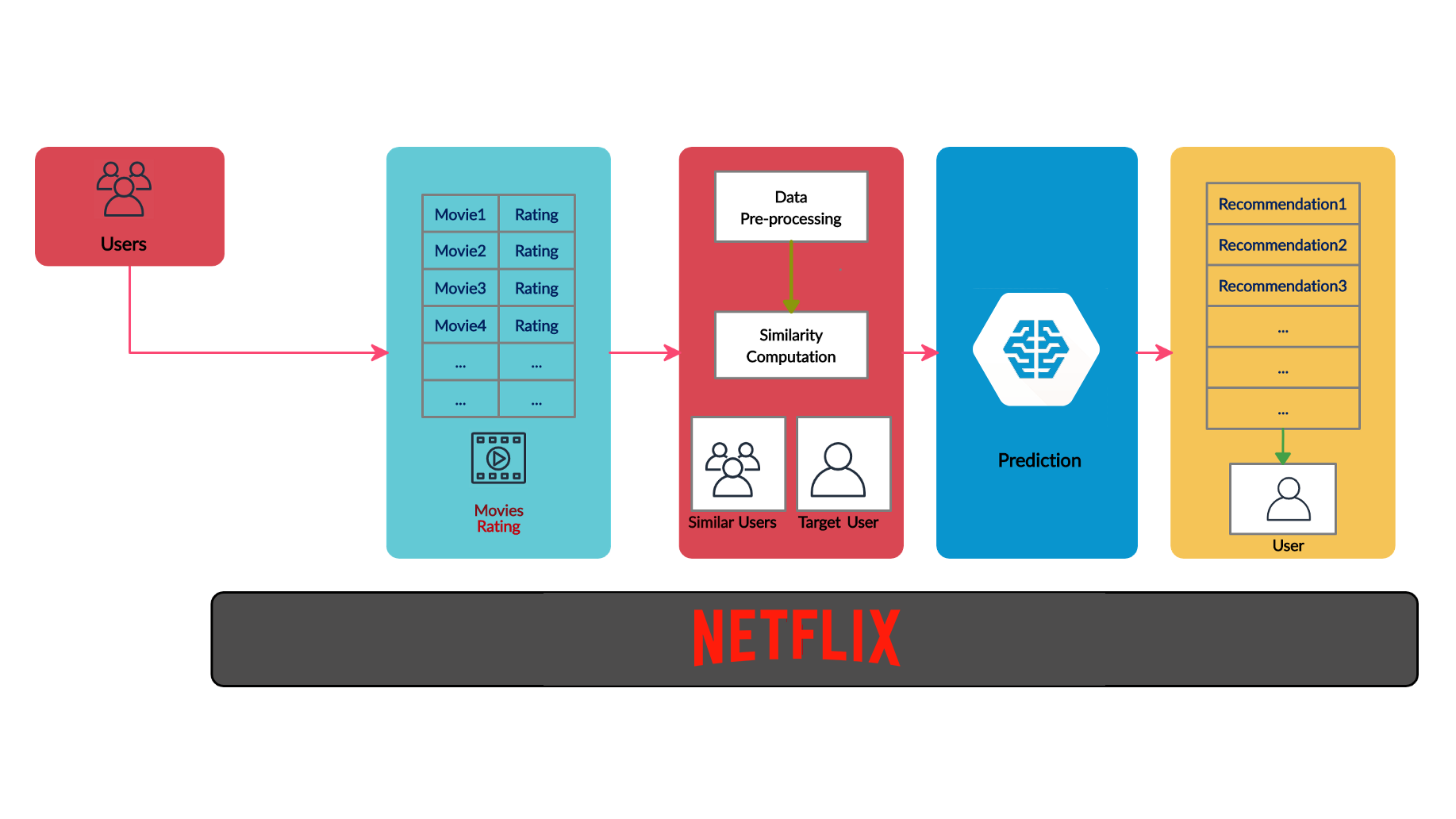
Image source: Width.ai
Factors to Consider When Choosing Reinforcement Learning for Your NLP Projects
The decision to implement a reinforcement learning system for NLP tasks depends on several factors. Here are some considerations to help you decide:
Complexity of the NLP Task: RL is often more suitable for complex NLP tasks where traditional rule-based or supervised learning approaches may not perform well. If your NLP task involves intricate decision-making, such as dialogue generation, machine translation, or text summarization, RL could be worth exploring.
Availability of Labeled Data: RL doesn't require large amounts of labeled data like supervised learning does. If you have a limited amount of labeled data for your NLP task, RL might be a viable option for training your model.
Reward Structure: You need to define a meaningful reward structure for your NLP task. This can be challenging, as designing an effective reward function is a critical part of RL. If you can clearly define what constitutes a good or bad outcome in your task, RL may be a good fit.
Computational Resources: Training RL models can be computationally expensive and time-consuming, especially when using deep reinforcement learning. Consider whether you have the necessary computational resources and infrastructure to support RL experiments.
Performance Improvement: Evaluate whether RL is likely to significantly improve the performance of your NLP system compared to other methods. Sometimes, simpler approaches like rule-based systems or supervised learning may suffice for certain NLP tasks.
Ethical and Safety Considerations: RL models can sometimes behave unpredictably during training, which can be problematic in applications like chatbots. Ensure you have mechanisms in place to handle and mitigate any unintended or unsafe behavior.
READ MORE: What Makes Google's Gemini the Next-level AI Model to Watch Out For?
Reinforcement Learning-Based NLP Is Expected To Grow
The implementation of reinforcement learning to solve the challenges of several NLP-based applications is only expected to expand exponentially in the years to come. There have been hundreds of research papers published in the public forums about successfully implemented reinforcement learning strategies.
AI solutions such as NLP are witnessing unending interest from not just scientists and innovators, but business stakeholders as well. To keep up with market trends through robust AI strategies for your software solutions, you can book a free consultation with us today.




