

The Artificial Intelligence (AI) ecosystem today is geared towards optimizing the capabilities of generative AI across various industries and everyday utility. Generative AI services are utilized for creating endless variations of ad copy, realistic image generation, refining low-quality images, and much more. Setting up the pace of generative AI advancement are Diffusion Models which help develop AI solutions that are pushing the boundaries of innovation.
In this article, we will first decode what diffusion models are, following which we will go on to discuss their various types, the dual bases of categorization, and also their real-world applications.
What Are Diffusion Models?
A diffusion model is a parameterized probabilistic model, which means that it can generate brand-new data based on the data that it is trained on. For instance, if the model is trained on images of the actual wonders of the world, it can create images of structures and monuments that do not actually exist. Pioneering AI-based tools such as DALL-E and Midjourney leverage diffusion models, particularly stable diffusion, to generate images from scratch.
A more complex explanation is that diffusion models are parameterized Markov chains trained with variational inference. Markov chains are mathematical models that form a system switching between states over certain intervals. So a diffusion model works by predicting the system's behavior over that time period, the system here refers to a sample set of media-based data. 
Image: Diffusion models moving to and fro between data and noise
A diffusion model is an example of a generative AI model that can create new data based on existing information fed to it. Another type of model that is similar but more specific to text-to-image generation is known as Vector Quantized Generative Adversarial Network (VQGAN).
While the application of VQGAN is limited to the area of text-to-image generation, diffusion models are more general in that they can generate new data irrespective of the media type from whatever data you input, be it images, videos, text, or music.
Researchers have used a combination of VQGAN and diffusion models to generate realistic, high-resolution images of fictional creatures and landscapes, which could have practical applications in fields like video game design, criminal investigation, or special effects for movies.
To put it simply diffusion models work along a two-step process:
- First, the input data is disintegrated until all that is left of it is noise.
- Following this, neural networks are applied to recover the input data from that noise which is leveraged to generate new data.

The Types of Diffusion Models
There are various types of diffusion models and while some are differentiated on the basis of the spread of a phenomenon across time and space another basis is the underlying mathematical framework. The first basis of differentiation is more generalized and does not pertain exclusively to the image or video generation and forms three types of diffusion models, namely:
1)Continuous Diffusion Models: Here, the spread of the phenomenon over time and space is smooth and continuous. They describe the rate at which the phenomenon, which most often is the adding and removing of noise from an image, is spread by a continuous function. The logistic diffusion model and the Bass model are examples of this.
2)Discrete Diffusion Models: The phenomenon that the model is trained on is assumed to be changing from one state to the other in discrete, incremental steps over a certain time period. Based on these incremental steps, a progression of the phenomenon is charted. The epidemic model and the percolation model are two examples of discrete diffusion models.
3)Hybrid Diffusion Models: Elements of both continuous and discrete diffusion models are combined in hybrid diffusion models. When it comes to real-world phenomena and finding complex yet tangible solutions, hybrid models are the go-to option. The agent-based model and cellular automaton model are examples of hybrid diffusion models.
The other basis for categorization takes into consideration the underlying mathematical formula for the model, dividing the models into the following categories:
1)Denoising Diffusion Probabilistic Models: DDPMs are primarily applied in image and signal processing tasks using a process wherein a simple distribution of phenomena is converted into a complex distribution that matches the data. The noise is reduced over time as the model gets trained on a large dataset, eventually learning to denoise the data. It sees its real-world applications in areas such as super-resolution, inpainting, and compression.
2)Noise-Conditioned Score-Based Generative Models: These models add Gaussian noise to a sample set of data and refine the data using estimated gradients. These gradients of the log-likelihood of the data result from a score function utilized by the generative model. Using a contrastive loss function, higher probabilities are assigned to the true data than the generative samples so that these models can be leveraged for image generation and other manipulation tasks.
3)Stochastic Differential Equation-Based Models: These differential equation-based models integrate random noise into the process of generating an image or forms of media. If the volume of a large dataset is prone to random fluctuations, these models provide a continuous-time evolution ensuring that the system remains stable after noise is removed.
Top 8 Applications of Diffusion Models
There is immense versatility and potential for the application of diffusion models in real-world use cases. This technology is advancing at breakneck speeds and with it, the list of potential use cases for this technology is also expanding. Here are some possibilities that this technology has unlocked in recent times:
Generating Images from Scratch
A large dataset of images is first fed into a diffusion model, an empty 116x16 grid is set up, and tokens are iteratively generated to fill up the grid. Generative diffusion models such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) can then learn the underlying probability distribution of the input dataset to produce new, never-before-seen synthetic images.

Image source: Images generated from scratch by Google's diffusion models
Inpainting and Conditional Image Generation
Conditional image generation refers to feeding the model a part of an incomplete or partially corrupted image. The model then takes the partial image as context to predict the next pixels one by one. The model may also predict discrete codes in a unidirectional for high-resolution image synthesis. Inpainting is more or less the same concept but it is used for 'fixing' images with unwanted portions by replacing parts of it with new pixels.
READ MORE: A Complete Guide to GANs: Types, Techniques, and Real-World Applications
High-Quality Video Generation
High-quality video generation is a matter of ensuring the high continuity of video frames. By applying diffusion models to this use case, a subset of video frames is generated to fill in for the missing frames in a low-quality video, leading to a smoother video with negligible latency. Low Frames Per Second (FPS) videos are converted to high FPS ones by adding newly generated frames that the model creates by learning from the data of the existing frames.
Text-to-Image Generation
Popular image-generation tools such as Midjourney and Stable Diffusion take input from the user in the form of text such as 'a blue umbrella in a desert setting' and using that prompt, produce images that can sometimes even be photorealistic. The diffusion model combines forces with a large language model to synthesize the user's textual prompt to convert it into an accurate image that is as close to relevant as possible.
Anomaly Detection
Diffusion models play a pivotal role in identifying deviations from expected behavior within datasets. These models leverage probabilistic techniques to establish a baseline understanding of what constitutes 'normal' data patterns. Once this baseline is established, deviations or anomalies can be effectively recognized by measuring how far data points diverge from this established norm. This application finds its utility in various sectors, including cybersecurity, disease detection, predictive maintenance in industrial machinery, and fraud detection in financial systems.
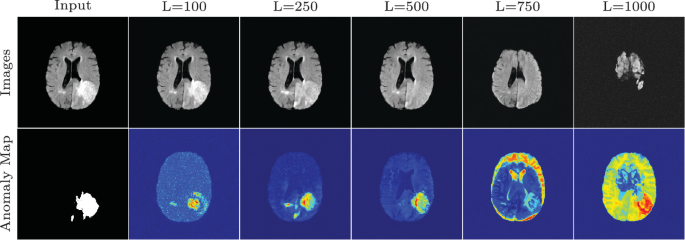
Image source: Springer Link

Drug Discovery
Scientists use diffusion models to understand how molecules move and interact in the body. These models simulate how molecules diffuse and react within biological systems, offering a comprehensive view of potential drug behavior. By accurately predicting molecular behavior, researchers can expedite the discovery of promising drug candidates. Diffusion models also aid in virtual screening, where vast databases of compounds are assessed for their potential to bind to specific drug targets. This computational approach significantly reduces the time and costs associated with bringing new medications to market.
Image source: Phys.org
Autonomous Vehicles
The application of diffusion models in Autonomous Vehicles represents a critical component of their autonomous decision-making systems. These models assimilate data from an array of sensors, including LiDAR, cameras, and radar, to create a dynamic representation of the vehicle's surroundings. Utilizing probabilistic modeling, diffusion models facilitate vital functions such as path planning, object detection, and collision avoidance. By predicting the future positions and behaviors of objects in real-time, autonomous vehicles can navigate safely through complex traffic scenarios, adhering to traffic rules and ensuring passenger safety.
Neuroscience Research
Diffusion models also find their application in the study of brain processes, cognition, and decision-making pathways of the human brain. Through the simulation of cognitive processes based on the neural basis of diffusion models, neuroscience researchers can gain insights into the underlying mechanisms. This in turn can lead to the enhancement of the diagnosis and treatment of neurological disorders.
ALSO READ: Generative AI Explained: How ChatGPT is Transforming Various Industries?
Limitations of Diffusion Models
1. Data Dependency - Diffusion models heavily rely on having a large and diverse dataset for training. This data dependency is a fundamental limitation because, without enough quality data, these models may not perform well. In many real-world scenarios, obtaining such comprehensive datasets can be challenging, particularly in niche or specialized domains.
2. Resource Intensive - Training and using diffusion models demand substantial computational resources. The complex computations required can strain both hardware and electricity resources. Running large-scale models often necessitates access to high-performance computing clusters or cloud resources, which can be costly and may not be readily available to all users.
3. Interpretability - Diffusion models are often regarded as "black boxes." This lack of interpretability is a limitation because understanding why these models make certain predictions or decisions is crucial, especially in critical applications such as healthcare, finance, and autonomous systems. The inability to provide clear and interpretable explanations for model outputs can limit their adoption in domains where transparency is essential.
4. Long-Term Dependencies - Diffusion models may struggle to capture and maintain long-range dependencies in data. For tasks where information from the distant past significantly influences the outcome, these models may not perform as well as recurrent neural networks (RNNs) or other architectures designed explicitly for handling sequential data.
5. Ethical Concerns - Generating highly realistic content using diffusion models can raise ethical concerns. These models have the potential to create deceptive or harmful content, including deepfakes and misinformation. Ensuring responsible use, content moderation, and preventing malicious applications are ongoing challenges.
6. Generalization - While diffusion models perform well on many tasks, they might not always generalize perfectly to new, unseen data. Achieving robust performance across diverse scenarios and domains is challenging because these models can be sensitive to variations in the data distribution. Researchers continuously work on improving the generalization capabilities of diffusion models, but this limitation highlights the need for careful evaluation and fine-tuning in practical applications.
Expand AI Capabilities With Diffusion Models
The field of diffusion models is constantly evolving with new breakthroughs observed on a near-weekly basis fueling further research opportunities. AI scientists are exploring more areas in the text, audio, and video-based applications where diffusion models can unlock a slew of enhancements. If you are looking to integrate cutting-edge AI capabilities into your enterprise digital solutions, you can begin your journey by booking a free consultation with Daffodil Software's AI Development Services team.




