
There are Yottabytes of sensitive data being generated from the interfacing of humans with machines. For cost-effective and optimal enrichment of this data, Machine Learning (ML) algorithms are our best bet. One of the most reliable categories of ML algorithms is clustering algorithms, irrespective of the complexity of data.
There are three different machine learning frameworks, classified based on the data you are working with - supervised learning, semi-supervised learning, and unsupervised learning. In supervised learning, the machine is trained with labeled data. The correct input and output data are provided to the machine.
Unsupervised learning works with data that is completely unlabeled, so it is left to the algorithm to find hidden patterns in the data. Semi-supervised learning is a combination of both the above machine learning approaches.
UPDATE: This article has been revised to include the latest findings in the field of ML.
What are Clustering Algorithms and When are They Used?
Clustering algorithms are unsupervised learning algorithms that find as many groupings in the unlabeled data as they can. These groupings are referred to as 'clusters'. Each cluster consists of a group of data points that are similar to each other based on their relation to surrounding data points.
Analysis that makes use of clustering algorithms may be especially pivotal when working with data that you know nothing about. Clustering algorithms are usually used when there are outliers to be found in the data or to do anomaly detection.

It is sometimes challenging to find the most suitable clustering algorithm for your data, but finding it will bring you indispensable insights into that data. Insurance fraud detection, categorization in libraries and warehouses, and customer segmentation are some real-world applications of clustering.
What are the Main Clustering Algorithm Models Based on Data Distribution?
As we have understood the fundamentals of clustering algorithms, we can get into their primary models or categories. These classifications arise based on the patterns that the data points need to be arranged in. The various clustering models are listed below:
- Density Model
The clustering algorithms built on the density model search for areas of varying density of data points in the data space. Data is then grouped by areas of high concentration of data points surrounded by areas of low concentration of data points. The clusters can be of any shape and there are no other constraints or data space outliers.
- Distribution Model
Under the distribution model, data is fit together based on the probability of how it may belong to the same distribution. In a particular distribution, a center point is determined, following which as the distance of a data point from the center increases, its probability of being in that cluster decreases.
- Centroid Model
This model consists of clustering algorithms wherein the clusters are formed by the proximity of the data points to the cluster center or centroid. The centroid is formed in such a way that the data points at the least possible distance from the center. Data points are differentiated based on multiple centroids in the data.
- Hierarchical Model
Hierarchical, or connectivity-based clustering, is a method of unsupervised machine learning that involves top-to-bottom and bottom-up hierarchies. These are implemented in hierarchical data from company databases and taxonomies. This model is more restrictive than the others, albeit efficient and perfect for specific kinds of data clusters.
Top 12 Clustering Algorithms
The foremost machine learning clustering algorithms are based on the above general models. The most fitting application of clustering algorithms would be for anomaly detection where you search for outliers in the data. Cluster analysis enables the discovery of patterns that you can use to find what stands out in the given data.
You can use clustering algorithms to solve other problems related to noise, interpretation, scalability, and so on. The most widely used clustering algorithms are as follows:
1)K-Means Algorithm
The most commonly used algorithm, K-means clustering, is a centroid-based algorithm. It is said to be the simplest unsupervised learning algorithm. Here, K defines the number of predefined clusters that need to be generated.
Each data cluster in the K-means algorithm is created in such a way that they are placed as far away as possible from each other. The data points in the clusters are allocated to the nearest centroid till no point is left without a centroid.
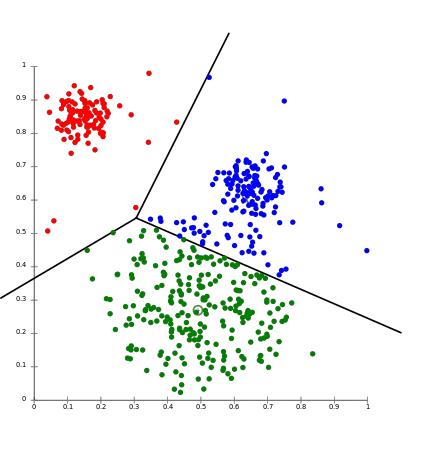
Image source: AmazonAWS
As long as the data has numerical or continuous entities, it can be analyzed with the K-means algorithm. In addition to being easy to understand, this algorithm is also much faster than other clustering algorithms.
Some drawbacks of this algorithm are incompatibility with non-linear data, outliers, and categorical data. Additionally, you need to select the number of data clusters beforehand.

2)Mean-Shift Algorithm
This is a 'sliding window' type algorithm that helps to find areas with high densities of data points. The algorithm works by updating the candidates for the centroid to be the center of points within a given zone or region in the data.
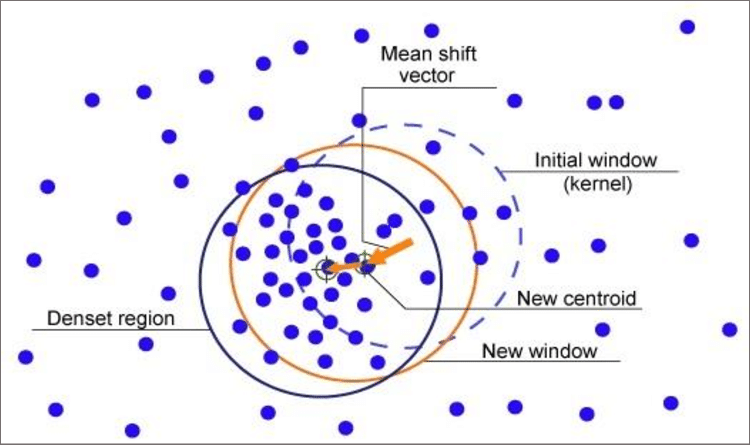
Image source: ResearchGate
The filtration of the candidate windows is done in the post-processing phase. The end result of this process is the formulation of a final set of centroids along with their allocated groups of data points.
The number of data clusters doesn't need to be determined before the data analysis begins with the algorithm, unlike the K-means algorithm.
3)DBSCAN Algorithm
This algorithm, which stands for Density-Based Spatial Clustering of Applications with Noise (DBSCAN), is similar to the Mean-shift. The DBSCAN algorithm separates the areas of high density from the low-density areas.
The clusters can then end up in any arbitrary shape. You will need a minimum number of points within the neighborhood of the starting data point to start the clustering process. Otherwise, those data points would end up as noise.
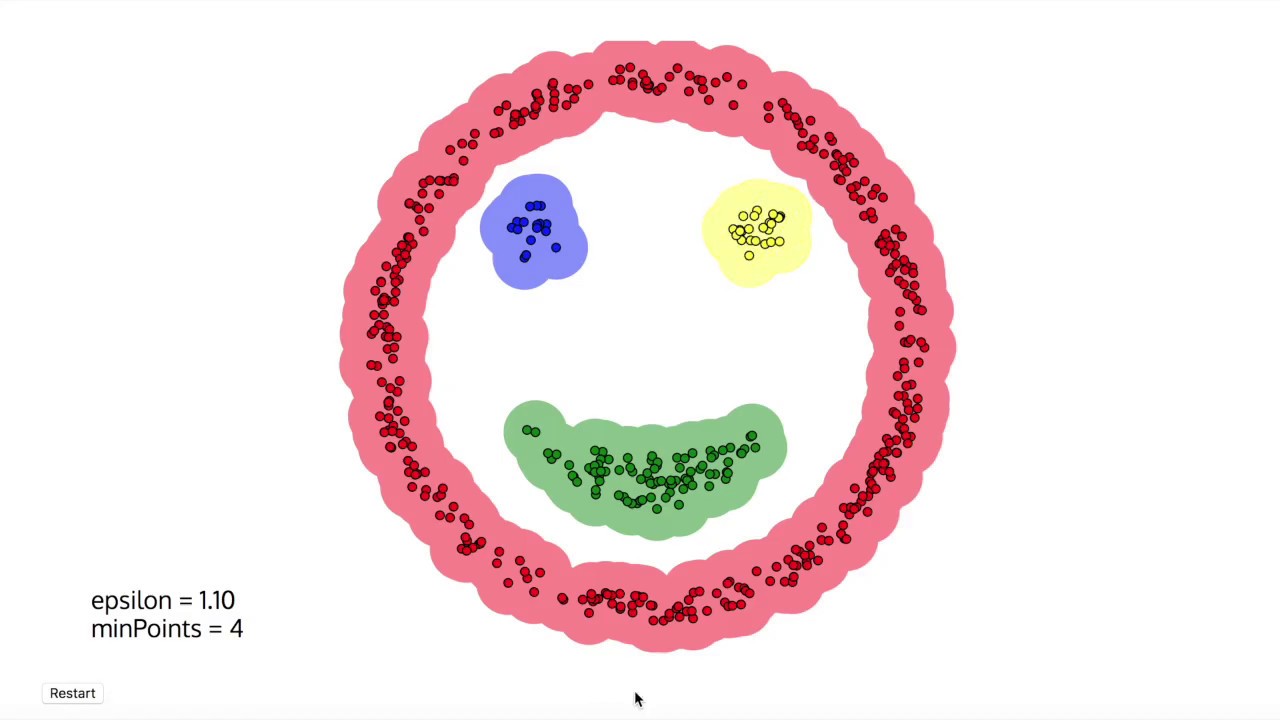
Image source: TheDataPost
This algorithm can identify outliers like noise and arbitrarily shaped and sized clusters with much ease. The DBSCAN algorithm also does not require a pre-set number of clusters.
4)Expectation-Maximization Clustering using Gaussian Mixture Models
This algorithm is used usually for those cases where the K-means clustering algorithm fails. The naive use of the mean value for the cluster center is the main disadvantage of K-means. K-means fail when the clusters are not circular and when mean values of the data cluster are too close together.
In Gaussian Mixture Models (GMM), it is assumed that the data points are Gaussian distributed. Both the mean and the standard deviation are used as parameters to describe the shape of the cluster.
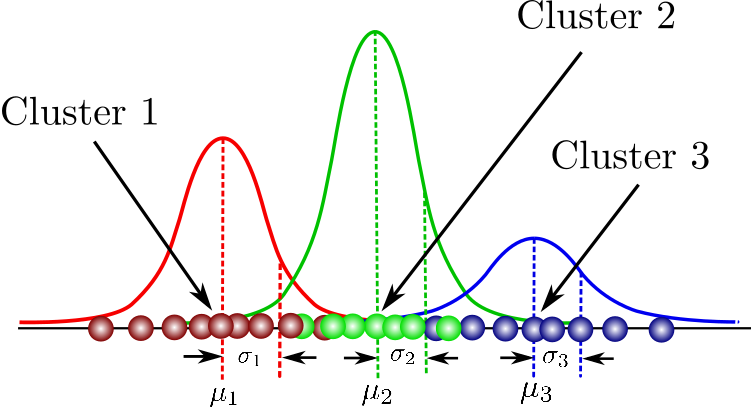
Image source: Towards Data Science
Each cluster mandatorily has a circular shape. Expectation-Maximization (EM) is an optimization algorithm that we use to find out the parameters of the Gaussian function. The cluster is then formed based on these parameters' values.
5)Agglomerative Hierarchical Algorithm
The Agglomerative Hierarchical Algorithm performs the function of bottom-up hierarchical clustering on data clusters. When the algorithm starts with the data, each of the data points is treated as a single cluster.
With every succession, the algorithm merges the data points into a tree-like structure. The merging continues to occur until finally a single group with all the data points is created.
The clusters with the smallest average linkage are merged into one. You do not need to specify the number of clusters at the outset and can select the best-structured clusters.
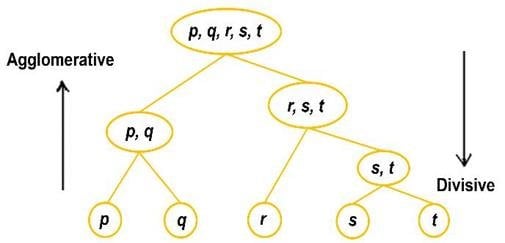
Image source: ResearchGate
6) Divisive Hierarchical Algorithm
Divisive Hierarchical Algorithm, often referred to as top-down hierarchical clustering, is a clustering technique that begins with all data points considered as a single cluster and then recursively divides this cluster into smaller, more focused subclusters. This process continues until each data point resides in its own individual cluster, forming a hierarchy or tree-like structure.
This top-down perspective can be advantageous in scenarios where the initial assumption is that all data points belong to a common group, and the objective is to uncover progressively more specific clusters within this larger context.
7) OPTICS Algorithm (Ordering Points To Identify Cluster Structure)
The OPTICS algorithm is a data clustering method that excels in identifying clusters without prior knowledge of their number or shape. It does this by measuring the reachability distance between data points. Starting with an arbitrary point, OPTICS creates a reachability plot, ordering points based on their reachability distances. This plot visually reveals clusters, with valleys in the plot indicating cluster boundaries.
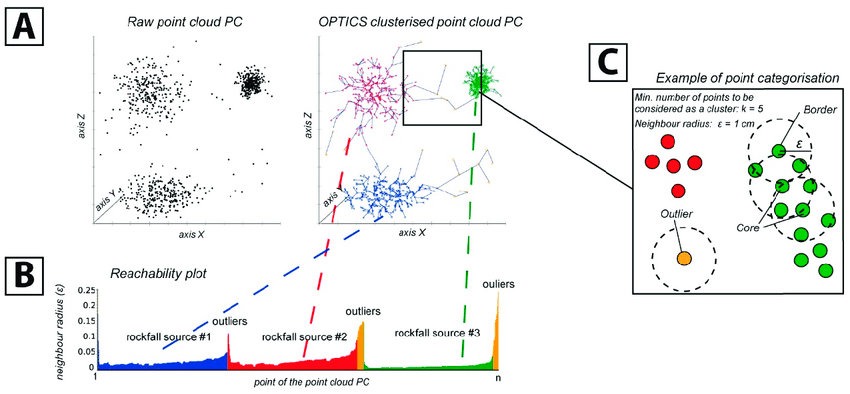
Image source: ResearchGate
This method is particularly beneficial in scenarios where traditional clustering algorithms might fall short due to the complex and varying nature of clusters. OPTICS delivers a hierarchical view of clusters, facilitating granular data exploration. Its applications span anomaly detection, density-based clustering, and in-depth data analysis.
8) Affinity Propagation
Affinity Propagation is a unique clustering technique that identifies clusters by selecting data points as exemplars or representatives. It employs a messaging system where data points communicate and cast "votes" to determine the most influential exemplars. The data points with the most significant cumulative votes become cluster centers.
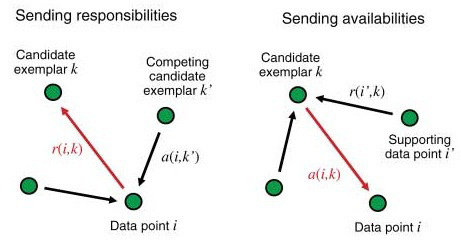
Image source: ResearchGate
This method is particularly useful in applications where pinpointing the most critical data points is crucial, such as identifying representative images in computer vision or key documents in text analysis. Affinity Propagation adapts dynamically to data, making it suitable for scenarios with varying cluster sizes and structures. It excels in tasks such as image recognition, document summarization, and pattern recognition.

9) BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies)
BIRCH is designed for the efficient processing of large datasets. Unlike traditional Hierarchical Clustering, BIRCH focuses on optimizing memory and computational efficiency while maintaining clustering accuracy.
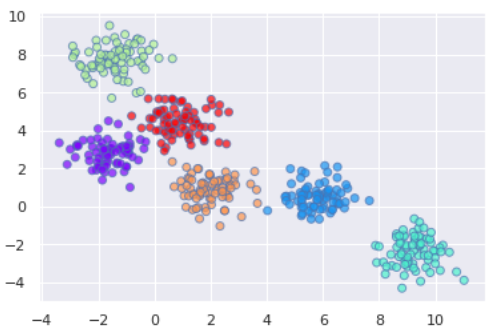
Image source: TDS
BIRCH constructs a hierarchical tree-like structure by incrementally merging data points into clusters. It uses a balanced approach, ensuring that clusters remain compact and manageable in size. This representation allows for efficient analysis of data at different levels of granularity. BIRCH is particularly valuable in scenarios where scalability and resource efficiency are essential, such as data warehousing and network traffic analysis. It streamlines the clustering process, making it suitable for large-scale data analysis without compromising on clustering quality.
10) Spectral Clustering
Spectral Clustering utilizes spectral graph theory to group data points based on pairwise similarities. It transforms the data into a spectral space, simplifying the clustering process. Spectral Clustering excels at capturing complex and non-convex cluster shapes, a limitation of traditional K-Means.
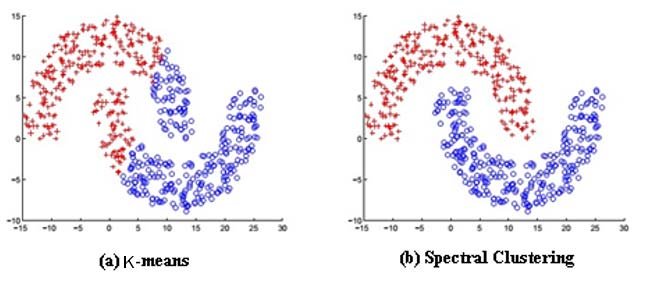
Image source: ResearchGate
This method offers flexibility, allowing users to specify the number of clusters or determine it automatically. It is useful in various applications, including image segmentation, social network analysis, and bioinformatics, where complex data structures require careful analysis.
ALSO READ: 10 Machine Learning Techniques for AI Development
11) Self-Organizing Maps
Self-organizing maps, often referred to as SOMs or Kohonen maps, are neural network-based models used for dimensionality reduction and clustering. They project high-dimensional data onto a lower-dimensional grid while preserving data relationships.
What sets SOMs apart is their ability to create a topological map of the input data. This means that not only do they group similar data points together, but they also preserve the spatial relationships between these points on the map. SOMs are excellent tools for exploratory data analysis, as they help uncover the underlying structure and patterns in complex datasets.
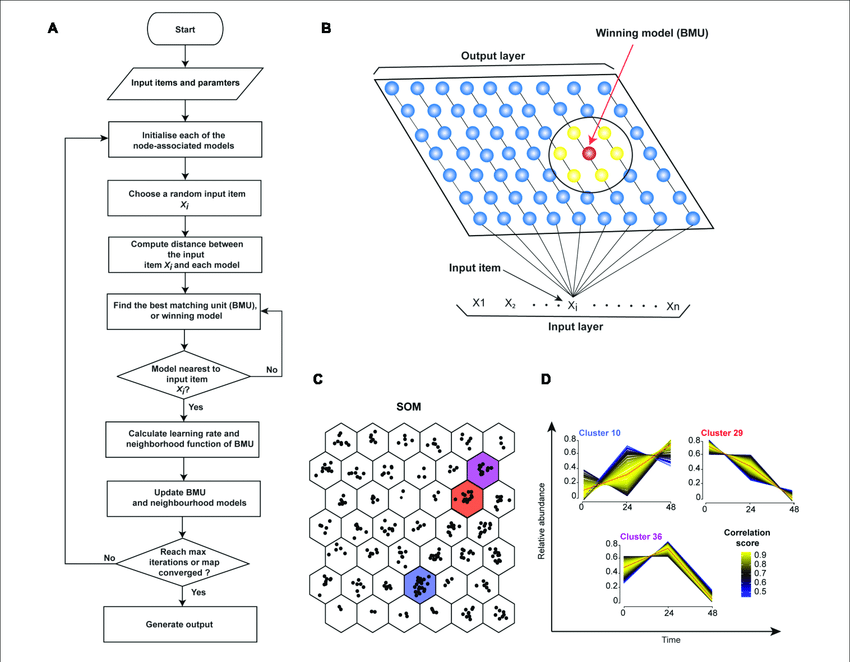
Image source: ResearchGate
12) Mini-Batch K-Means
Mini-batch K-Means is a variant of the classic K-Means algorithm optimized for processing large datasets efficiently. Instead of analyzing all data points simultaneously, Mini-Batch K-Means samples smaller subsets, called mini-batches, for cluster assignment and centroid updates.
This approach significantly accelerates the clustering process while maintaining results nearly as accurate as traditional K-Means. It is ideal for scenarios where computational resources or time constraints necessitate faster clustering. Mini-Batch K-Means finds application in fields like image processing, customer segmentation, and recommendation systems, where timely analysis is crucial.
Building Machine Learning Models for your Software Solutions
Nearly every business, established and emerging alike, is realizing the benefit of digitization with the latest technologies. The ease and efficiency of data analysis with machine learning algorithms is one such advantage.
Machine learning models and algorithms are the backbones of any Artificial Intelligence-based software application or modernization project. To begin the journey of modernizing your software solutions you can book a consultation with Daffodil's AI experts.




