

The unprecedented proliferation of data generated by various digital sources has left businesses grappling with the complexities of managing large volumes of data. According to a report by IDC, the digital universe data is expected to reach 180 zettabytes by 2025. This massive amount of data presents significant challenges for organizations in terms of storage, processing, and analysis.
Traditional or legacy data architectures and tools are no longer sufficient to handle the sheer volume and complexity of data that organizations are dealing with today. That's where modern data stacks come in - A modern data stack is a comprehensive set of tools, technologies, and processes that enable businesses to improve their data management capabilities, derive insights from their data, and facilitate growth.
In this blog, we will discuss what a modern data stack is, how it differs from legacy data stacks, how it is built, its benefits, and its real-life use cases.
What is Modern Data Stack?
A modern data stack is a comprehensive and flexible infrastructure of data tools that work in harmony to enable businesses to collect, store, process, and analyze their data efficiently and quickly.
The key components of a modern data stack typically include a cloud-based data warehouse, data pipelines, and analytics and business intelligence (BI) layers. These components are designed to be modular, robust, and flexible enough to be independently swapped out or modified as needed to achieve the organization's data goals.
The primary aim of a modern data stack is to help businesses save time, money, and effort by providing a scalable, unified, and agile approach to managing and analyzing data. By leveraging a modern data stack, organizations can integrate cloud-based data sources with legacy and on-premises solutions, enabling end-users to access governed data on trusted platforms with minimal configuration.
Modern Data Stack vs Legacy Data Stack
| Feature | Legacy Data Stack | Modern Data Stack |
| Data Processing | It uses batch processing. | It uses real-time processing, streaming analytics, and machine learning. |
| Data Storage | It has a centralized data warehouse. | It has distributed, scalable storage such as cloud-based solutions. |
| Tools and Technologies | It uses relational databases, ETL tools, and BI tools. | It uses data ingestion tools (e.g. Apache Kafka), data processing frameworks (e.g. Apache Spark), data analytics and visualization tools (e.g. Tableau), and machine learning frameworks (e.g. TensorFlow). |
| Agility | It has limited flexibility. | It is highly flexible and adaptable to changing data needs. |
| Cost | The costs of software licensing and hardware used in this system are high. | It has lower costs and relies on cloud-based solutions and open-source tools. |
| Data Volume | It is not suitable for handling large and complex datasets. | It is compatible with both large and small datasets. |
| Data Access | It is typically limited to selected users. | It is accessible to a broader range of users, including non-technical users. |
| Data Sources | It is limited to structured data from internal systems. | It can handle a variety of data types and sources, including unstructured and semi-structured data from both internal and external sources. |
| Development | Traditional data stacks may require significant development time and expertise. | Modern data stacks may provide more user-friendly interfaces and require less development time and expertise. |
| Maintenance | Traditional data stacks may require significant maintenance, including hardware updates and software upgrades. | Modern data stacks may require less maintenance due to their cloud-based architecture and receive automatic updates and patches. |
Components of Modern Data Stack Architecture
Modern data stack architecture is an end-to-end data processing and analytics platform that enables organizations to ingest, process, store, and analyze vast amounts of data in a scalable, efficient, and cost-effective way. It comprises several components that work together to form a cohesive system. Here are the key components of a modern data stack architecture:
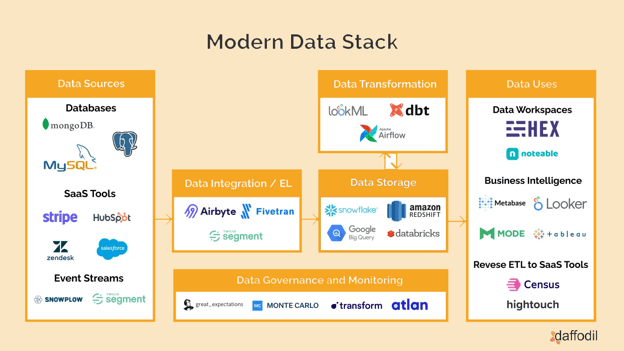
Data Sources
Data sources refer to the different systems and platforms from which data originates. It can come from multiple sources such as social media platforms, IoT devices, third-party data providers, internal systems such as CRM, ERP, or HR, and many more.
The value of data sources lies in their ability to equip organizations with critical insights regarding their customers, operations, and business performance. This helps companies to optimize their strategies, refine their products and services, and ultimately drive business growth.
However, collecting data from multiple sources can be challenging, as data may be stored in different formats, have varying levels of quality, or require different access methods. Therefore, modern data stack architecture typically includes tools and technologies for data integration and ingestion, which allow organizations to collect data from different sources and load it into a central repository or data warehouse.
Data Integration
Data integration is a critical aspect of modern data architecture, which involves the amalgamation of data from multiple sources into a cohesive and unified view. It involves a set of technologies, processes, and practices that allow organizations to combine data from diverse internal and external sources and load it into a centralized place.
By merging data from different sources, organizations can eliminate data silos, reduce redundancy, enhance data quality, and establish a single version of the truth.
Some popular tools for data integration are Fivetran, Airbyte, and Segment.
There are several approaches to data integration, including:
1. Extract, Transform, and Load (ETL): This involves extracting data from various sources, transforming it into a common format, and loading it into a target system such as a data warehouse.
2. Extract, Load, and Transform (ELT): This approach is similar to ETL, but it involves loading the data into a target system first and then transforming it. ELT can be more efficient than ETL in some scenarios because it reduces the time taken to transform the data.
3. Application Programming Interfaces (APIs): APIs enable different software applications to communicate and exchange data in real-time. This approach is ideal for organizations that need to integrate data from cloud-based applications or external data sources.
4. Data Virtualization: With data virtualization, organizations can access data from various sources without the need to physically combine it. This method creates a virtual view of the data, which is beneficial for organizations that require immediate data integration or access to information dispersed across multiple systems.
ALSO READ: What is an ETL Tool and Why is it Necessary for Business Growth?
Data Storage
In modern data stack architecture, data storage is an essential component that refers to the process of storing data in a structured and organized manner for easy retrieval and use.
It typically employs a distributed and cloud-based approach, utilizing a range of data storage technologies, such as relational databases, NoSQL databases, data warehouses, and data lakes. The adoption of modern data storage solutions facilitates seamless data integration and provides organizations with secure, reliable, and scalable data storage.
The data storage layer is typically interconnected to other layers, such as data ingestion, data processing, and data visualization, through APIs and connectors. This enables smooth data movement across different layers, allowing organizations to extract insights and value from their data.
There are various popular cloud warehouses such as Snowflake, Google’s bigQuery, and Amazon Redshift which serve as the central component of the data stack.
Additionally, these data storage solutions offer various data management capabilities, such as backup and recovery, data replication, and disaster recovery, to ensure the availability and integrity of data.
Data Transformation
Data transformation refers to the process of converting raw data from disparate sources into a more accessible, usable, and standardized format that can be leveraged for analysis and decision-making.
The data transformation process typically involves several stages, including data cleaning, data mapping, data normalization, and data enrichment. During these stages, raw data is transformed into a consistent format that can be utilized for predictive analytics.
There are various data transformation tools such as dbt, Apache Airflow, LookML, and Databrick’s Delta Live tables. By leveraging such solutions, organizations can transform data at scale, reduce processing time, and increase the accuracy of results.
Data Governance and Monitoring
Data governance refers to the management of data assets and their associated policies, standards, and procedures. It is essential for ensuring that data is accurate, reliable, and consistent across the organization, while also complying with relevant regulatory requirements.
It relies on a range of tools and technologies to facilitate data governance, including data cataloging, data lineage, and data classification tools. With these solutions, organizations can effectively manage their data assets, including identifying their origins, tracking data changes over time, and classifying and protecting their data.
Data monitoring, on the other hand, refers to the ongoing monitoring and analysis of an organization's data assets to ensure their integrity and security. This includes detecting and addressing anomalies, identifying potential security threats, and taking corrective action as necessary.
ALSO READ: Why Observability Matters in Site Reliability Engineering (SRE)
Data Uses
Data plays a pivotal role in driving business value and enabling organizations to make data-driven decisions. The use of data in modern data architecture is multifaceted and encompasses a wide range of applications and use cases.
By analyzing data from various sources, organizations can better understand their customers’ needs and behaviors. Moreover, it can develop predictive models that can forecast future trends and outcomes, identify anomalies and outliers, and automate decision-making processes. Thus, it helps improve operational efficiency, reduce costs, and increase profitability.
Benefits of Modern Data Stack
Some of the benefits of using a modern data stack include:
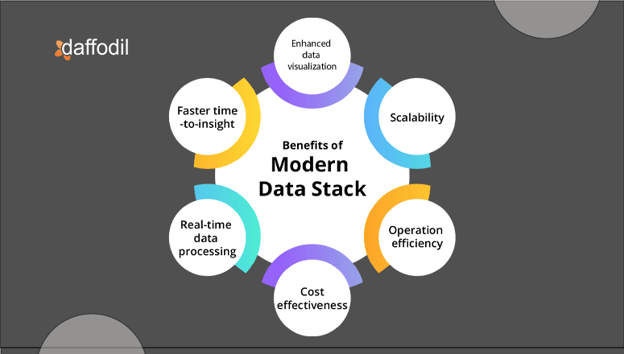
1. Scalability: The modern data stack is equipped to manage large data volumes. It provides the agility to adjust to evolving business demands, making it an ideal solution for businesses that require scalable data management capabilities.
2. Cost-effectiveness: It can help businesses save on on-premise infrastructure and maintenance costs, as they can be hosted in the cloud and require fewer resources to manage and maintain.
3. Faster time-to-insight: Modern data stacks include powerful tools for data processing and analysis, which can help organizations get insights faster, allowing them to make better decisions in a timely manner.
4. Real-time data processing: By leveraging advanced technologies, such as distributed computing and in-memory processing, it can process data in real-time more quickly and efficiently. This can significantly be useful for applications such as fraud detection, predictive maintenance, and real-time monitoring of operational performance.
5. Data visualization: Modern data stacks often include data visualization tools, making it easier for users to visualize and communicate insights in a clear and meaningful way. This can help stakeholders understand the data more easily and make better-informed decisions.
6. Operational efficiencies: It can enable businesses to optimize their operations by providing valuable insights into various key performance indicators, such as production efficiency, supply chain performance, and customer service. By analyzing these KPIs, businesses can identify areas that need improvement and implement changes that can lead to increased operational efficiency and cost reduction.
Use Cases of Modern Data Stack
1. Netflix
Netflix uses a variety of cloud-based services to process and analyze vast amounts of data generated by its users, such as their viewing habits, ratings, and searches. The company's data stack includes Amazon Web Services (AWS) as its primary cloud provider, along with other tools and technologies for data storage, processing, and analytics.
Netflix leverages AWS services such as Amazon S3 for storing data, Amazon EC2 for computing power, and Amazon Redshift for data warehousing. The company also uses its own open-source tools such as Genie and Lipstick to manage data processing and workflow orchestration. Additionally, Netflix uses a range of machine learning algorithms to personalize content recommendations to its users.
The implementation of a modern data stack has enabled Netflix to better understand its customers' preferences, improve content recommendations, and optimize its content creation and distribution. This has helped Netflix to become one of the most successful streaming platforms, with over 200 million subscribers worldwide.
2. Spotify
Spotify employs a modern data stack to collect and analyze data about its users' listening habits, such as the artists they listen to, how often they skip tracks, and which playlists they create. The company's data stack includes tools such as Apache Kafka, Apache Flink, and Google BigQuery, which enable real-time data processing and analytics.
Spotify uses Apache Kafka to collect and store data about its users' listening habits in real-time. It then uses Apache Flink for real-time data processing and analytics, allowing the company to generate personalized recommendations and optimize its music catalog. Additionally, Spotify uses Google BigQuery to store and query large amounts of data, enabling the company to quickly extract insights and make data-driven decisions.
Optimize your Data Processes
With the exponential growth of data volume, velocity, and variety, a modern data stack provides a scalable and flexible solution to manage and analyze data effectively. By investing in a modern data stack, businesses can simplify their data management processes, enhance their operational efficiency, optimize their marketing and sales strategies, and ultimately increase conversions.
If you're interested in adopting a modern data stack architecture, Daffodil can help you evaluate your current data infrastructure and recommend the best solutions to meet your business needs. Check out our Software Development Services and book a free consultation with us to take the first step toward transforming your data management processes.




